

«Есть три вида лжи: ложь, наглая ложь и статистика»,
Марк Твен (Mark Twain)
Несколько недель назад одна из компаний списка Fortune 500 попросила Клэр Вигнон Кезер (Claire Vignon Keser), аналитика данных и специалиста по машинному обучению, проанализировать их программу сплит-тестирования.
Результаты тестов выглядели неплохо, гипотезы казались сильными, все было в порядке… на первый взгляд. Пока Клэр не просмотрела журнал изменений в инструменте тестирования. Там Клэр заметила несколько ошибок. Так, в некоторых экспериментах маркетологи скорректировали распределение трафика для вариаций в середине теста. Некоторые вариации останавливались на несколько дней, затем возобновлялись. Кроме того, эксперименты прекращались по достижению статистической значимости.
Когда дело доходит до тестов, слишком многие компании беспокоятся о вопросе «что?» (например, о дизайне тестовых версий), но недостаточно заняты вопросом «как?», или самим процессом эксперимента.
Да, дизайн тестовых версий крайне важен. Вам нужны твердые гипотезы, подтвержденные сильными доказательствами. Однако если вы считаете, что стоит придумать тестовые версии, нажать кнопку запуска — и на этом работа кончается, то вы ошибаетесь. Фактически, то, как вы проводите сплит-тесты — важнейшая часть работы оптимизатора.
В этом посте мы расскажем о самых больших ошибках, которые вы можете допустить на каждом шаге сплит-теста: разработке, запуске и анализе эксперимента. А также о том, как избежать этого. Данная статья довольно технична и информативна. Вот как стоит ее читать:
- Если вы только знакомитесь с понятиями оптимизации конверсии (CRO) и не принимаете непосредственного участия в разработке и анализе тестов, не стесняйтесь пропускать технические разделы.
- Если вы — эксперт в области CRO или участвуете в разработке и анализе тестов, вам необходимо обратить внимание на технические детали.
Ошибка №1: у вашего теста слишком много вариаций
Чем больше вариаций мы протестируем, тем больше информации получим, верно? Не совсем. Слишком большое число версий замедлит производительность ваших тестов. К тому же, это может повлиять на целостность данных.
Чем больше вариаций вы столкнете друг с другом, тем больше трафика вам понадобится и тем дольше придется поддерживать тест для получения убедительных результатов. Это просто математика.
Но проблема с проведением более длинных тестов заключается в файлах cookie. Чем дольше проводится тест, тем выше риск получить «грязные» результаты. Если эксперимент длится больше 3-4 недель, то за это время люди могут удалить свои файлы cookie и снова перейти на ваш ресурс, увидев на этот раз другую версию тестируемого элемента.
«За две недели число людей, которые могли удалить cookie и теперь способны повлиять на качество вашей выборки, вырастает до 10%», Тон Весселинг (Ton Wesseling), основатель Online Dialogue.
Второй риск при тестировании нескольких вариантов заключается в том, что уровень значимости снижается по мере роста числа изменений. Например, если вы используете общепринятый уровень значимости в 0,05 и решили протестировать 20 сценариев, то один из них достигнет уровня значимости случайно (20 * 0,05). А если вы тестируете 100 сценариев, то это число вырастает до пяти (100 * 0,05). Другими словами, чем больше вариаций, тем выше число ложных срабатываний, как и шансы назначить победившей неэффективную вариацию.
Хороший пример — 41 оттенок синего. В 2009 году, когда Google не мог решить, какие оттенки синего будут генерировать наибольшее число кликов на странице выдачи поисковых результатов, маркетологи корпорации решили протестировать 41 оттенок. При уровне достоверности 95%, вероятность получения ложного положительного результата составила 88%. Попробуй маркетологи Google 10 оттенков, вероятность получить ложное подтверждение составила бы 40%. Аналогично, 9% с тремя оттенками и менее 5% с двумя оттенками.
Это называется проблемой множественного сравнения (Multiple Comparison Problem).
Вы можете посчитать вероятность получения ложного положительного результата, используя следующую формулу:
1-(1-a)^m,
где m — общее количество проверенных вариантов, a — уровень значимости. При коэффициенте значимости 0,05, уравнение будет выглядеть так:
1-(1-0.05)^m или 1-0.95^m.
Обойти проблему множественного сравнения позволяет поправка Бонферрони (Bonferroni correction), которая вычисляет уровень достоверности для отдельного теста при проверке более одного варианта или гипотезы.
Википедия иллюстрирует поправку Бонферрони следующим примером:
«Если экспериментатор проверяет гипотезы, и желаемый уровень значимости для всего семейства тестов равен a, то поправка Бонферрони будет проверять каждую отдельную гипотезу на уровне значимости a/m»
Например, если вы тестируете m = 8 гипотезу с желаемым а = 0,05, то поправка Бонферрони проверит каждую отдельную гипотезу при а = 0,05/8 = 0,00625».
Другими словами, вам понадобится уровень значимости 0,0625%, который совпадает с уровнем достоверности 99,375% (100% – 0,625%) для индивидуального теста. Поправка Бонферрони довольно консервативна и основана на предположении, что все тесты не зависят друг от друга. Тем не менее, она демонстрирует, как несколько сравнений способны исказить ваши данные, если вы неверно измеряете уровень значимости.
В следующих таблицах суммирована проблема множественного сравнения.
Вероятность ложноположительного результата при уровне значимости 0,05:
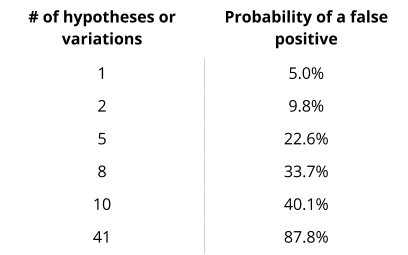
Левая колонка: номер гипотезы или вариации.
Правая колонка: вероятность ложного подтверждения.
Уровни значимости и достоверности, необходимые для поддержания 5%-ной вероятности ложного положительного результата, представлены в таблице ниже:
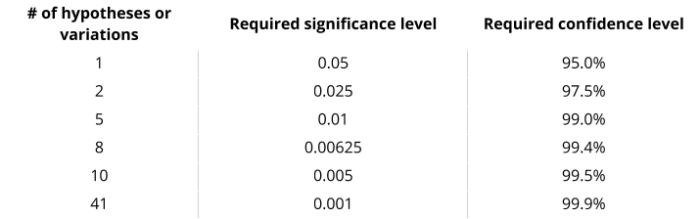
Левая колонка: число гипотез или вариаций;
Средняя колонка: необходимый уровень значимости;
Правая колонка: необходимый уровень достоверности.
Еще одна проблема с тестированием нескольких вариантов может встать перед вами при анализе результатов теста. У вас может возникнуть соблазн объявить победителем вариант с наибольшим ростом результатов — даже если между победителем и вторым финалистом нет статистически значимой разницы. Это значит, что даже если один вариант смотрится лучше в текущем тесте, занявший второе место может победить в следующем раунде.
Поэтому стоит воспринимать оба варианта в качестве победивших.
Ошибка №2: вы меняете настройки эксперимента в середине теста
Запустив эксперимент, доведите его до конца. Не изменяйте характеристики эксперимента, его цели или дизайн вариаций в середине теста. И не меняйте распределение трафика на варианты.
Изменение распределения трафика между вариациями во время эксперимента повлияет на целостность ваших результатов. Это произойдет из-за проблемы, известной как «парадокс Симпсона» (Simpson’s Paradox). Этот статистический парадокс появляется, когда мы наблюдаем тенденцию в разных группах данных — но при объединении групп тенденция исчезает.
Ронни Кохави (Ronny Kohavi) из Microsoft делится примером сайта, который получает миллион посетителей ежедневно, включая пятницу и субботу. В пятницу 1% трафика направляется на тестовую версию, а в субботу этот процент увеличивается до 50%.
Несмотря на то что тестовый вариант показывает более высокую конверсию, чем контрольный, как в пятницу (2,30% против 2,02%) так и в субботу (1,2% против 1,00%), при объединении данных за два дня, результаты, по-видимому, ухудшаются (1,20% против 1,68%). Это связано с тем, что мы имеем дело со средними значениями. Данные субботы (день с худшей конверсией) повлияли на тестовую версию больше, чем данные пятницы.
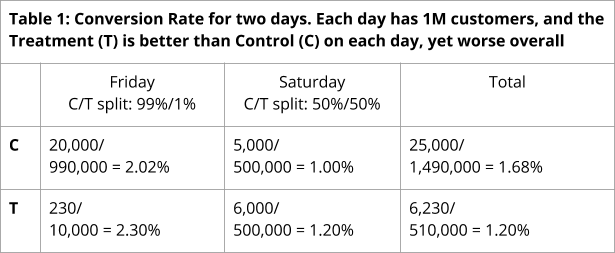
Таблица 1: коэффициент конверсии за два дня. Каждый день приходит 1 миллион посетителей. Тестовая версия лучше контрольной на каждый отдельный день, но в общем конверсия контрольного варианта лучше.
Вернемся к парадоксу Симпсона немного позже.
Также изменение трафика в середине теста исказит ваши результаты, поскольку это изменит выборку возвращающихся посетителей.
Изменения, внесенные в распределение трафика, влияют только на новых пользователей. После того, как посетители увидят другую вариацию, они будут продолжать видеть ее весь срок работы эксперимента.
Итак, скажем, вы запускаете тест, выделив 80% трафика на контрольную и 20% на тестовую версию. Затем, через несколько дней, вы измените это распределение на 50/50. С этого момента все основные пользователи будут распределены соответственно.
Тем не менее, пользователи, вошедшие в эксперимент перед изменением, будут видеть тот же вариант, что и ранее. В нашем текущем примере это означает, что вернувшиеся посетители по-прежнему будут привязаны к контрольной версии, т.е вы повысили число вернувшихся пользователей (которые вероятнее конвертируются), на вариацию А.
Примечание: эта проблема распределения трафика в середине теста возникает только в том случае, если вы вносите изменения на уровне вариации. На уровне эксперимента вы можете вносить изменения в середине теста. Это полезно, если вы хотите создать период повышения трафика — нацелив 50% в первые несколько дней, чтобы затем увеличить долю до 100%. Это не повлияет на целостность ваших результатов.
Как упоминалось ранее, «правило середины эксперимента» распространяется на цели теста и дизайн вариаций. Отслеживая несколько целей в процессе теста, вы можете захотеть изменить основную цель в середине эксперимента. Не делайте этого.
У любого оптимизатора есть любимая вариация, победы которой он втайне желает. Это не проблема, пока вы не начнете придавать повышенный вес метрикам, благоприятствующим этому варианту. Определите метрики цели, измеримые в краткосрочной перспективе (продолжительность теста) и которые способны предсказать ваш успех в долгосрочной перспективе. Отслеживайте и придерживайтесь их.
Полезно отслеживать и другие ключевые показатели, чтобы получать информацию и/или корректировать эксперимент, когда что-то пойдет не так. Однако это не те показатели, на которые нужно обращать особое внимание — даже если они поддерживают ваш любимый вариант.
Ошибка №3: неверная сегментация после тестирования
Допустим, вы избежали предыдущих двух ошибок. Теперь вы уверены в результатах, которые видите. Пришло время проанализировать их, не так ли?
Не так быстро! Вы остановили тест, как только он достиг статистической значимости? Надеемся, что нет.
Статистическая значимость не должна диктовать вам, когда останавливать тест. Она лишь сообщает, есть ли разница между контрольным и тестовым вариантами. Вот почему вам не следует ждать, когда тест достигнет значимости (потому что этого может не случиться) или прекращать эксперимент сразу после достижения значимости. Вместо этого, дождитесь, когда будет достигнут вычисленный размер выборки. Используйте калькуляторы продолжительности теста, чтобы понять, когда эксперимент можно останавливать.
Теперь, предполагая, что вы остановили тест в правильное время, мы можем перейти к сегментации. Сегментация и персонализация — горячие темы современного маркетинга, поэтому все больше и больше инструментов сплит-тестирования обеспечивают их.
Из этого следует, что после остановки теста вы, вероятно, начнете анализировать результаты на основе таких сегментов, как источник трафика, новые и вернувшиеся посетители, тип устройства и пр. Этот метод называется пост-тестовой сегментацией и является одним из трех путей создания гипотез персонализации и сегментации для тестирования.
Однако существует две основных проблемы с сегментацией после теста. Они влияют на статистическую достоверность ваших сегментов:
- Величина выборки сегментов слишком мала. Вы остановили тест, достигнув расчетного размера выборки, но на уровне сегмента размер выборки, вероятно, слишком мал, а лифтинг между сегментами не имеет статистической достоверности.
- Проблема множественного сравнения. Чем больше сегментов вы сравниваете, тем выше вероятность того, что вы получите от них ложный положительный результат. При уровне достоверности 95% вы, вероятно, получите ложное подтверждение на каждые 20 рассмотренных сегментов после теста.
Существуют разные способы предотвращения этих двух проблем. Но самая легкая и точная стратегия — создание целевых тестов (а не разбивка результатов по сегментам после теста).
Мы не выступаем против пост-тестовой сегментации — совсем наоборот. На деле, изучение слишком большого объема совокупных данных может ввести в заблуждение (парадокс Симпсона наносит ответный удар).
В статье Википедии о парадоксе Симпсона представлен реальный пример из медицинского исследования, в котором сравниваются показатели успеха двух методов лечения камней в почках. В таблице ниже представлены показатели успешности лечения и количество вариантов, работающих как с крупными, так и с мелкими камнями в почках.
Парадоксальный вывод заключается в том, что вариант А более эффективен при использовании его на небольших и больших камнях по-отдельности, а версия В эффективна при одновременном анализе обоих сегментов. В контексте сплит-теста это будет выглядеть примерно так:

Названия колонок слева направо: посещения страницы А; посещения страницы В; конверсии страницы А; конверсии страницы В; коэффициент конверсии страницы А; коэффициент конверсии страницы В.
Парадокс Симпсона часто появляется при неравномерной выборке — когда размер выборки ваших сегментов различен. Есть несколько способов борьбы с этим эффектом.
Во-первых, можете исключить проблему радикально, используя стратифицированную выборку, которая формируется разделением членов популяции на однородные и взаимоисключающие подгруппы перед выборкой. Однако известные инструменты редко предлагают такую опцию.
Если вам пора определяться, действовать ли по совокупным данным или по данным сегментов, то вы можете смотреть не на цифры, а на историю за пределами цифр.
Так, в примере выше — стоит воздержаться от принятия решений с данными в таблице. Вместо этого, лучше посмотреть на каждую пару «источник трафика/лендинг» с квалифицированной точки зрения. Основываясь на характере каждого источника трафика (разовый, сезонный, стабильный), вы можете прийти к другому окончательному решению. Например, к возможности сохранения обеих посадочных страниц, но для разных источников
Чтобы сделать это с учетом данных, нужно рассмотреть каждую пару «источник/страница» как отдельную тестовую вариацию, и некоторое время проводить дополнительные тесты, пока не будет достигнут желаемый статистически значимый результат по каждой паре.
В двух словах, непросто провести пост-тестовую сегментацию правильно, но если вы этого добьетесь, она покажет то, чего не откроют совокупные данные. Помните, что вам придется проверять данные по каждому сегменту в отдельном контрольном тесте.
Вместо заключения
Исполнение эксперимента — наиболее важная часть успешного процесса оптимизации. Если ваши тесты не были проведены должным образом, то результаты станут невалидными — и вы будете полагаться на вводящие в заблуждение данные.
Хорошие результаты всегда заманчивы — и часто обманчивы. В большинстве случаев, именно по результатам босс или заказчик оценивает успех оптимизации конверсии. Но результаты не всегда заслуживают доверия. Очень часто цифры, которые вы видите в тематических исследованиях, не подкреплены достоверными статистическими выводами. Они слишком сильно опираются на ненадежный инструмент сбора сплит-статистики и/или не учитывают распространенные ошибки, перечисленные в этой статье.
Используйте кейсы как источник вдохновения, но убедитесь, что собственные тесты вы проводите правильно. Поможет в этом простой чек-лист:
- Если ваш инструмент сплит-тестирования не учитывает проблему множественного сравнения, обязательно исправьте уровень значимости для тестов с более чем одной вариацией;
- Не меняйте настройки теста в середине эксперимента;
- Не используйте статистическую значимость как индикатор времени остановки теста, и убедитесь, что рассчитали размер выборки, который необходимо достичь, прежде чем завершать тест;
- Наконец, продолжайте сегментировать данные после теста. Но убедитесь, что вы не попали в ловушку множественного сравнения, что сравниваете сегменты, достигшие значимости и имеющие достаточно большой размер выборки.
Высоких вам конверсий!
По материалам: widerfunnel.com Источник изображения: Internet Archive Book Images



















