



Какое будущее ждет графические пользовательские интерфейсы (graphical user interfaces, GUIs) с появлением голосовых интерфейсов, чат-ботов и систем искусственного интеллекта? Несмотря на некоторые мрачные предсказания, графические интерфейсы не исчезнут еще много лет. Сегодня мы рассмотрим несколько прогнозов по внедрению мультимодальных интерфейсов как более современных способов человеко-компьютерного взаимодействия.
Первичные сенсоры
Изображение стоит тысячи слов — эта старая мудрость актуальна и сегодня. Мы воспринимаем сложную информацию быстрее, когда видим ее визуально. Согласно исследованиям, даже когда мы разговариваем с кем-то лично, невербальная коммуникация занимает две трети от всего процесса общения. В соответствии с другими исследованиями, большую часть информации мы воспринимаем визуально (83% — глазами, 11% — на слух; 3% — обонянием; 2% — осязанием, 1% — на вкус). Словом, глаза — наши первичные сенсоры.
Вторые, но не по значению, сенсоры — уши. В некоторых случаях общение голосом — самый эффективный канал связи. Представьте процесс заказа пиццы. Он будет гораздо проще, если вы позвоните в пиццерию по телефону, а не станете проходить все этапы онлайн-покупки на сайте. Но в более сложных ситуациях одного голосового общения недостаточно. Например, купили бы вы ботинки, не увидев и не примерив их сначала? Вероятно, нет.
Даже традиционно текстовые платформы обмена сообщениями начали вводить визуальные элементы. Не случайно, что визуальные фрагменты пользовательского интерфейса первым реализовал Facebook, создав свою чатбот-платформу. Некоторую информацию гораздо проще понять, увидев ее.
Текстовые и голосовые интерфейсы удобны в некоторых случаях, но на сегодняшний день стало ясно, что они не универсальны. Пока визуальное восприятие доминирует и пока мы сохраняем навык визуальной обработки сложной информации, графические интерфейсы останутся. С другой стороны, более традиционные шаблоны GUI не выживут в их нынешней форме. Вместо радикальных прогнозов, предлагаем другую идею: пользовательские интерфейсы станут более адаптированными под наши сенсоры.
Адаптивные мультимодальные интерфейсы
Люди, как и компьютеры, обладают разными устройствами ввода-вывода информации. Наши глаза и уши — главные сенсоры входа. Мы прекрасно распознаем образы и обрабатываем изображения. Это означает, что мы можем быстрее обрабатывать сложную информацию визуально. С другой стороны, на звук мы реагируем быстрее, поэтому голос — хороший вариант для передачи срочных данных и предупреждений.
У нас есть и устройства ввода информации: мы способны говорить и жестикулировать, писать и печатать. Голос — наиболее эффективное устройство ввода из имеющихся у нас, потому что большинство людей говорит быстрее, чем печатает или жестикулирует.
Поскольку людям свойственно сочетать разные каналы, можно предсказать, что машины будут следовать этому и использовать мультимодальные интерфейсы для адаптации к возможностям человека. Эти интерфейсы станут задействовать различные каналы ввода и вывода для разных сред и типов информации.
Интерфейсы будут адаптироваться к людям, используя среду и формат сообщений, которые наиболее удобны для людей в данной ситуации. Рассмотрим несколько примеров.
Чат-боты становятся все более визуальными
Nuru — это концепция чат-бота, помогающего жителям Африки в повседневных проблемах. Начав проектирование, разработчики быстро столкнулись с ограничениями текстовых интерфейсов. Для базового общения чат более эффективен, чем традиционные пользовательские интерфейсы. Например, в Африке чаты полезны для развития локальной торговли.
Продавцы и покупатели могут встретиться и обсудить детали сделки — для этих целей чат станет оптимальным решением, из-за формата общения «тет-а-тет». Но если дело доходит до более сложных взаимодействий, например, сравнения нескольких задач, то понадобится более продвинутый интерфейс. Для этих случаев в чат-интерфейс Nuru были добавлены карточки, доступные для прокрутки.
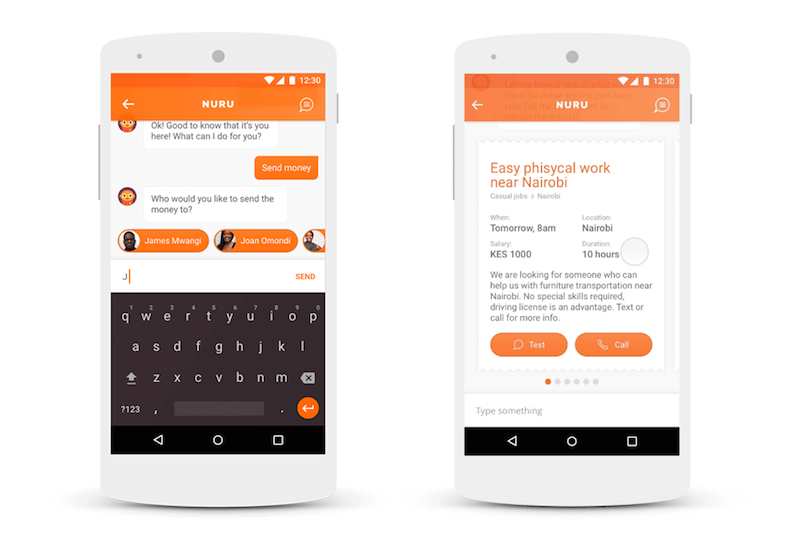
Некоторые другие компании, как Tencent в Китае, пошли еще дальше и позволили разработчикам создавать собственные мини-приложения, которые запускаются внутри чат-приложения WeChat. Это вдохновило западных дизайнеров на создание диалогового интерфейса, в котором каждое сообщение могло содержать другое приложение, каждое со своим собственным интерфейсом. Например, так вы сможете сыграть в мини-игры с партнером по чату. Также это новшество улучшает и расширяет функционал диалоговых интерфейсов.

Беспилотные автомобили со смешанными интерфейсами
В прошлом году одна дизайн-команда представила интерфейс беспилотного автомобиля, как упражнение в мультимодальном проектировании. Команда спроектировала процесс и попыталась оптимизировать взаимодействия на каждом этапе.
Чтобы заказать автомобиль, вы нажмете кнопку на телефоне — этого простейшего взаимодействия хватит, чтобы вызвать машину. Очевидно, что нет необходимости в телефонном разговоре, если можно просто нажать кнопку. Затем, попав в салон автомобиля, вы устроитесь поудобнее, разместите свои вещи и пристегнете ремень безопасности. На этом этапе устное общение будет более удобным — автомобиль спросит, куда вы направляетесь. Это быстрее сказать, чем вводить местоположение на сенсорном экране. Для того, чтобы функция работала верно, автомобиль должен понимать любые, даже самые неоднозначные инструкции.
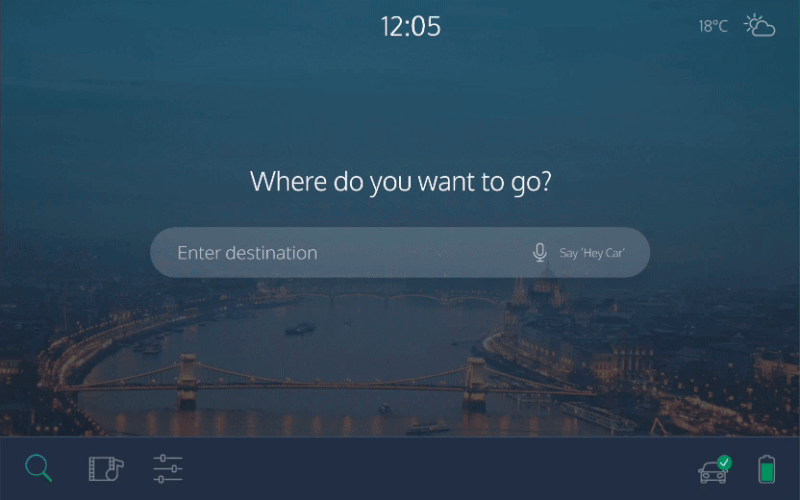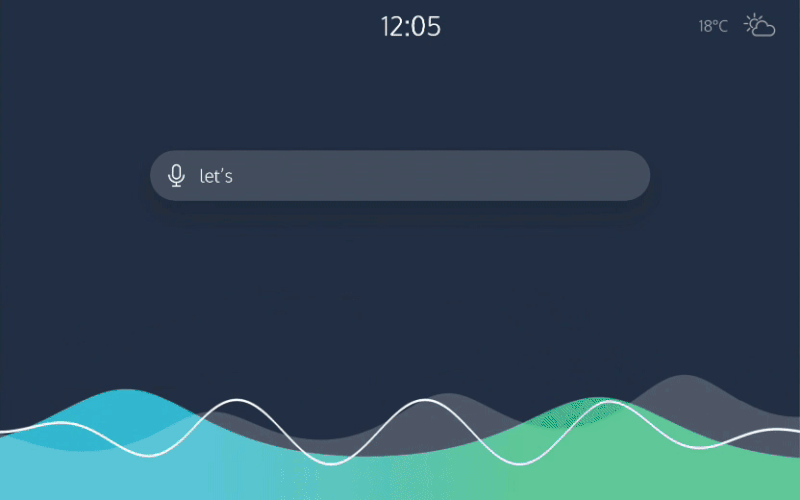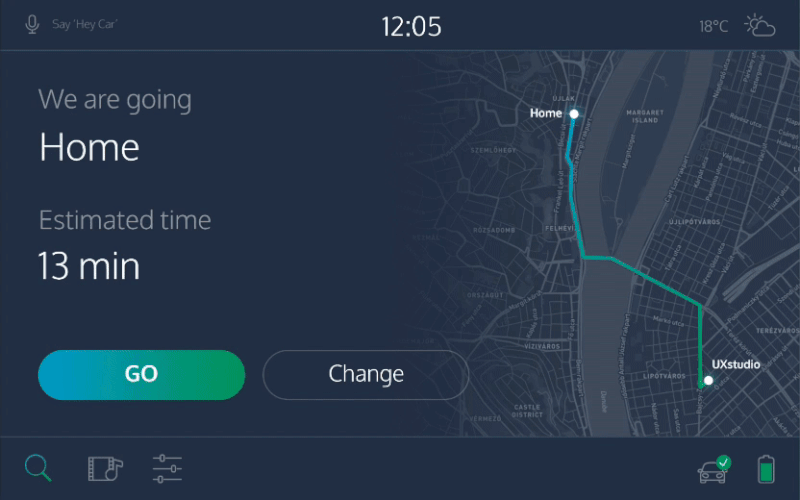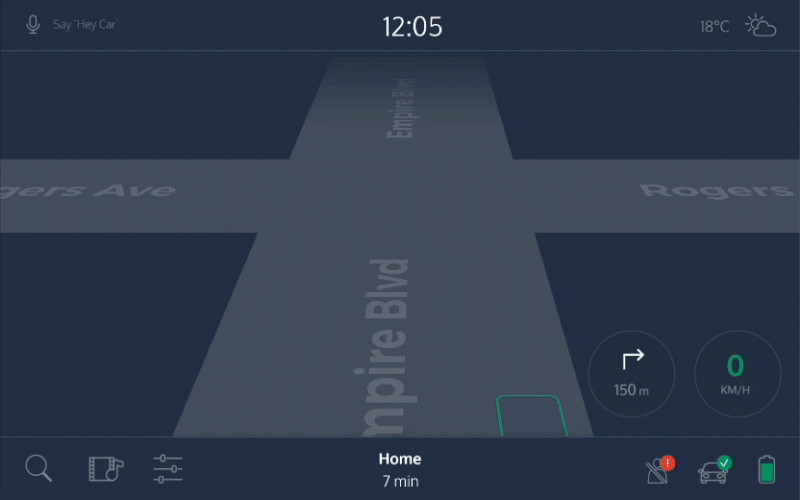
Доверие — важный аспект взаимодействия с беспилотными авто. В пути мы хотим быть уверенными, что машина движется в правильном направлении и знает путь к цели. Но уточнять эту информацию у системы каждый раз, когда авто сворачивает на странный маршрут, неудобно. Планшетный интерфейс, видимый всем пассажирам, решит эту проблему. На нем изображен автомобиль, его маршрут и положение на карте. Таким образом будет строиться доверие пассажира к системе.
В этом примере, вы можете заказать машину с помощью сенсорного экрана, задавать ей голосовые команды, получать звуковую обратную связь и проверять статус поездки на экране.
Домашние развлечения и цифровые ассистенты
Консоль Xbox с контроллером Kinect — еще один пример смешанного интерфейса. Вы можете управлять процессом с помощью голоса и движениями рук. В ролике ниже вы увидите, что технология распознавания жестов еще не идеальна, но в будущем она, безусловно, улучшится. Распознавание голоса также немного несовершенно, потому что перед каждой командой вы должны произносить «волшебное слово» — «Xbox».
Несмотря на технические недостатки, это хороший пример того, как система может давать постоянную визуальную обратную связь на голос и жесты. Когда вы используете свою руку в качестве элемента управления, на экране появляется маленькая рука-курсор. Перемещаясь, этот курсор подсвечивает блоки контента, что показывает, какой из них можно активировать в данный момент. Когда вы произносите «Xbox», чтобы задать команду, над каждым элементом появляется окно со списком возможных команд, чтобы вы знали, что сказать в данном случае.
Конечно, цель всего перечисленного — помочь человеку в управлении голосовым интерфейсом. В будущем, более точное распознавание голоса и обработка языка позволят людям задавать команды своими словами. Это важный шаг к широкой популяризации смешанных интерфейсов.
Amazon, без сомнения, входит в число величайших пионеров голосовых интерфейсов и интерфейсов «без GUI». Но даже эта компания добавила экран к новому поколению устройств Echo, после неудачной попытки внедрить GUI на телефоны пользователей.
Свобода, которую дает голосовой пользовательский интерфейс, действительно завораживает, особенно при первом знакомстве с технологией. Например, сказать «Включи Red Hot Chili Peppers» во время готовки гораздо проще, чем прокручивать плейлист грязными руками.
Но спустя время, когда вы захотите использовать голосовой интерфейс для более сложных задач, он попросту не сработает. В одном ролике пользователь отметил, насколько странно, что каждый раз, запуская кухонный таймер, вы должны запрашивать статус устройства — поскольку экрана нет. Теперь, благодаря Echo Show, мы можем видеть несколько таймеров на одной панели.
И что для Amazon важнее шоппинга? С помощью старого Echo, вы могли добавить список покупок, но затем вам требовалось открыть мобильное приложение, чтобы купить что-то. Слушать, как Alexa зачитывает длинные описания продуктов Amazon — ужасный опыт. Теперь же эти задачи упростились, потому что система показывает продукты на экране и вы можете легко выбрать нужный.

В отличие от Xbox Kinect, Echo Show является первичным голосовым устройством. Его домашний экран не заполнен значками приложений. Но когда вы отправляете начальную голосовую команду, экран отображает всю связанную с ней информацию. Это очень просто: когда вам нужно узнать больше, вы просто смотрите на экран. Процесс похож на то, как человек работает с приложением на кухне. Сосредоточенный на приготовлении пищи, он может поддерживать базовую коммуникацию голосом. Но когда возникает необходимость в сложной или важной команде, человек останавливается и смотрит на экран. И поэтому поворот Echo Show в сторону мультимодального интерфейса выглядит естественно и своевременно.

Еще одна деталь дизайна. На главном экране Echo отображает заголовок новости и выделяет одно из слов заголовка жирным шрифтом. Это командное слово, которое нужно сказать, чтобы услышать всю новость. Echo эффективно устанавливает ожидания и дает советы через визуальный интерфейс.
Одним из основных преимуществ продукта Google Home, главного конкурента Echo, является то, что после вопроса: «Сколько людей живет в Будапеште?» вы также можете спросить «Как там погода?». Система поймет, что вы спрашиваете об одном и том же месте. Понимание контекста — отличная функция, которая станет обязательной составляющей продуктов будущего.
Разработка интерфейса, считывающего контексты, позволит устранить трение. Будет ли продукт использоваться на кухне, когда руки пользователя заняты? Да, ведь ему доступно голосовое управление, которое даже проще сенсорного. Но обратится ли пользователь к голосовому интерфейсу в переполненном поезде? В таких условиях сенсор будет гораздо удобнее голосового помощника. Пользователю нужен простой ответ на простой вопрос? Пусть обратится к диалоговому интерфейсу. Ему нужно видеть изображения и сложные данные? Поместите их на экран. Чтобы улучшить взаимодействие, стоит задавать вопросы. Например, какой формат и экран лучше подходят для данной операции.
Одна важная функция, которая все еще отсутствует в Google Home — поддержка нескольких пользователей. Устройства, подобные этому, будут использоваться разными людьми, возвращая нас к феномену семейного компьютера на заре эры ПК. Переключение между пользователями станет непростой задачей. Безопасность и высокий UX нелегко выровнять. Представьте, что вы разговариваете с голосовым помощником, имеющим доступ ко всем вашим приложениям и данным, а затем кто-то другой входит в комнату и делает то же самое.
Amazon Echo и Google Home дают приятную визуальную обратную связь: когда они слушают вас или ищут ответ, вы видите светодиодную анимацию. Для мультимодальных интерфейсов важно поддерживать синхронизацию голосовых и визуальных форматов вывода данных. В противном случае, люди легко запутаются. Например, когда мы разговариваем с кем-то, нам легко понять, что собеседник уловил суть сообщения, по выражению его лица. Вероятно, нам захочется того же при общении с продуктом.
Продукты для здоровья
PD Measure — приложение для измерения зрачкового расстояния у людей, которые носят очки по рецепту. Хороший пример синхронизации и объединения визуальных и голосовых интерфейсов.
Любой клиент должен знать свое зрачковое расстояние, чтобы приобрести очки онлайн. В противном случае, клиенту придется идти в розничный магазин и там измерять этот показатель. Но инструмент измерения, доступный любому в домашних условиях, открывает огромные перспективы для рынка онлайн-оптики.
С помощью PD Measure, клиент может сфотографировать себя, стоя перед зеркалом, а затем, следуя точным инструкциям, получить расчет зрачкового расстояния по расширенному алгоритму приложения. Результат достаточно точен для заказа очков в интернете.
Пользовательский интерфейс PD Measure представляет собой комбинацию анимированных иллюстраций на экране, показывающих, как держать телефон, и голосовых инструкций, рассказывающих, что делать дальше. Пользователь должен поместить руки в правильное положение, после чего приложение даст обратную связь. Когда приложение одобрит фото, пользователь также получит звуковую обратную связь. Таким образом, пользователь привыкает к звуку подтверждения действий и станет быстрее работать с приложением.
На этапе прототипирования разработчики провели множество тестов и выяснили, что люди более склонны следовать голосовым инструкциям, нежели визуальным.
В этом примере визуальные и голосовые интерфейсы работают вместе: анимированные показывают, как держать телефон, а голосовые подсказывают правильное положение для снимка.
Другие примеры
Еще в 2013 году компания Volio экспериментировала со смешанными интерфейсами. Одним из ее ведущих клиентов был журнал Esquire, который создал интерактивный опыт, позволяющий читателям общаться с обозревателями издания. Как показано в ролике ниже, это была серия видео — но вы могли выбрать запись, исходя из ответа на вопрос в предыдущем видео. Конечно, допускался выбор только из нескольких предопределенных ответов, но интерактивность все равно ощущалась, а опыт воспринимался почти как живой разговор.
Многие воспринимают мультиэкранные интерфейсы как отдельные каналы для своего контента. Но смешанные интерфейсы станут гораздо более значимыми. Люди смогут использовать ваше приложение на разных устройствах одновременно. Например, применять голосовой ввод Alexa при просмотре данных на экране.
Таким образом, комбинация голосового и графического интерфейсов также не будет нужна. Одно из приложений для просмотра спортивных состязаний позволяет людям комментировать футбольный матч и общаться с другими фанатами со смартфона, наблюдая за игрой в прямом эфире на Smart-TV. Два экрана, в данном случае, прекрасно дополняют друг друга.
Такие продвинутые интерфейсы предлагают функциональность, доступную сразу нескольким устройствам и медиа. Некоторая избыточность этого подхода разочаровывает дизайнеров и программистов, но у него есть преимущества. Это дает людям возможность резервного копирования, если основной девайс недоступен. Также это помогает инвалидам, которые не могут использовать голосовые или визуальные интерфейсы.
Как выбрать первичный режим?
Мы обсудили тенденции на примерах реальных продуктов. Теперь суммируем, когда лучше использовать голос, а когда — визуальный интерфейс. Визуальные пользовательские интерфейсы работают лучше для:
- списков со множеством составляющих (чтение всех пунктов вслух займет слишком много времени)
- сложной информации (графики, диаграммы, данные со множеством атрибутов);
- предметов для сравнения или для выбора;
- продуктов, которые нужно увидеть перед покупкой;
- данных о процессах, которые нужно периодически проверять (время, таймер, скорость, маршрут и пр.)
Голосовые пользовательские интерфейсы работают лучше для:
- команд (ситуаций, в которых вы точно знаете, чего хотите);
- инструкций для пользователя (люди охотнее следуют голосовым инструкциям, нежели письменным);
- звуковой обратной связи об успешном или ошибочном действии;
- предупреждений или уведомлений (потому что реакция на голос быстрее);
- простых вопросов, которые требуют относительно простых ответов.
Что дальше?
Некоторые дизайнеры считают первым примером смешанного интерфейса легендарную разработку MIT Media Lab от 1979 года, «The Put That There». Эта технология получила рабочий прототип 38 лет назад. Значит ли это, что мы переоцениваем темпы прогресса?
Распознавание голоса все еще имеет очевидные проблемы, и только несколько основных игроков предоставляют платформы для продуктов с голосовыми интерфейсами, включая приложения (WeChat) и аппаратные продукты (Amazon Echo). Хорошая идея на будущее — разработка приложения или бота, который интегрируется с этими системами. Вот несколько других советов:
- Заложите в основу продукта скорость и точность.
- Синхронизируйте визуальные и голосовые интерфейсы. Всегда давайте обратную связь о происходящем.
- Показывайте визуальные индикаторы процессов (когда устройство слушает пользователя или ищет ответ).
- Выделите слова-команды в графическом интерфейсе.
- Задайте правильные ожидания пользователей о возможностях интерфейса и убедитесь, что продукт объясняет, как их использовать.
- Продукт должен считывать физический и социальный контекст устройства и разговора, и реагировать соответственно.
- Подумайте о контекстах, в которых находится пользователь, и определите, какой носитель и устройство устранят трение и максимально упростят задачу.
- Предоставьте пользователям возможность доступа к функциям через альтернативные устройства или носители. Это поможет в ситуациях поломок и сбоев, а также сделает продукт доступным для людей с ограниченными возможностями.
- Не игнорируйте безопасность и конфиденциальность. Разрешите людям отключать компоненты интерфейса (например, микрофон) и укрепите их доверие. Не становитесь слишком назойливыми, чтобы не раздражать пользователей.
- Не озвучивайте длинные монологи, если та же информация может быть кратко изложена в нескольких словах. В таком случае, разместите ее на экране.
- Поймите специфику каждой платформы и выберите правильный вариант.
Но прежде, чем приступать к работе, учтите — мультимодальные интерфейсы все еще неизведанная область.
Во-первых, для создания смешанных интерфейсов у нас до сих пор нет общего языка или структуры программирования. Такой язык позволит определять элементы голоса и GUI в одной когерентной кодовой базе, что упростит проектирование и разработку этих интерфейсов, а также обеспечит поддержку множества параметров входа и выхода, позволяющих разрабатывать многоканальные, многоэкранные и мульти-устройства.
Во-вторых, дизайнеры должны создать новые шаблоны, соответствующие особым потребностям мультимодальных интерфейсов. Например, как предоставить визуальную и звуковую обратную связь в одно и то же время?
Хотя будущее выглядит захватывающим и оно наступит быстро, нам все равно нужно достичь определенного уровня в распознавании голоса и обработке естественного языка. Важно, чтобы удобство использования речевой среды достигло того уровня качества, на котором этот вариант станет лучшим для приложений и пользователей. Нам также понадобятся лучшие инструменты для проектирования и кодирования мультимодальных интерфейсов. Как только мы достигнем этих целей, ничто не сможет сдержать данные интерфейсы и они быстро станут основными.
История повторяется, но кто в нее войдет?
Технологии и интерфейсы, которые обращаются к нескольким органам чувств, смогут глубже вовлечь пользователя во взаимодействие с системой.
Подобная мультимодальная эволюция происходила и раньше. Радио и немое кино слились в звуковой кинематограф, который изменился с приходом 3D. Схожие процессы мы наблюдаем в цифровом мире прямо сейчас.
Высоких вам конверсий!
По материалам: smashingmagazine.com Источник картинки: Sabine Israel















