


В этой статье мы рассмотрим четыре ловушки анализа данных, распространённые в SEO-отрасли, и расскажем, как их избежать.
1. Поспешные выводы
В 2017 году было проведено исследование, которое посвящалось роли ссылок в ранжировании Google, и опубликовано следующее:
«Тот факт, что Domain Authority (или объемы брендового поиска, или что-либо еще) положительно коррелирует с ранжированием, может говорить о вероятности одного или всех приведенных ниже утверждений:
- Ссылки позволяют сайтам хорошо ранжироваться
- Хорошее ранжирование приводит к появлению ссылок на сайтах
- Некий третий фактор (к примеру, репутация или возраст сайта) приводит к тому, что сайты получают и ссылки, и позиции в поисковиках».
Немного углубимся в это заявление и посмотрим, какие ошибки допускаются при интерпретации данных, полученных таким образом.
Во-первых, мы довольно часто становимся жертвами предвзятости подтверждения (confirmation bias): когда мы видим успешные сайты, заполненные ключевиками, то опираемся на клише «корреляция против причинности», но мы склонны одобрять результаты исследований, делающие то же самое с тем, что, по нашему мнению, было или является эффективным — например, ссылками.
Прежде чем принимать решения на основе той или иной корреляции, вы должны учесть разные возможные варианты:
- Полная случайность
- Обратная причинность
- Совместная причинность
- Линейность
- Широкая применимость
Рассмотрим этот подход на примере выявленной корреляции между потреблением сыра на душу населения и количеством людей, которые умерли, запутавшись в своих простынях.
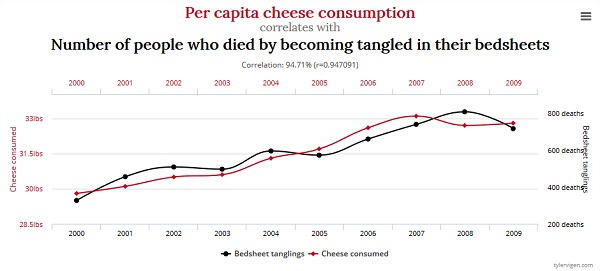
Прежде чем вы перестанете кушать сыр, опасаясь умереть от этого в постели, вам нужно проверить каждый из приведенных ниже вариантов:
- Совпадение — возможно ли, что было сопоставлено так много наборов данных, что некоторые из них могли быть похожими? Да, такое может быть.
- Обратная причинность — возможно ли, что мы ошибаемся? К примеру, быть, может, ваши родственники, оплакивая вашу смерть, едят сыр в больших количествах, чтобы успокоиться? Это кажется маловероятным.
- Совместная причинность — возможно ли, что какой-то третий фактор стоит за этими двумя? Может, повышение благосостояния улучшает ваше здоровье (и вы не умираете от таких вещей, как недоедание) и заставляет вас есть больше сыра. Это кажется очень правдоподобным. Да, это возможно.
- Линейность — сравниваем ли мы два линейных тренда? Линейный тренд — это устойчивый темп роста или снижения. Любые два статистических результата, которые являются примерно линейными по времени, будут очень хорошо коррелироваться. Если графики составлены с использованием разных шкал, они могут выглядеть совершенно несвязанными. Но поскольку они оба имеют равномерный характер, они всё равно будут хорошо коррелироваться. Да, это похоже на правду.
- Широкая применимость — возможно ли, что это отношение существует только в нишевых сценариях? Например, сыр приводит к смерти некоторых людей, и этого было достаточно, чтобы создать корреляцию, так как существует мало смертельных случаев, связанных с удушением в постели? Да, это кажется возможным.
Итак, мы получили 4 ответа «Да» и 1 ответ «Нет». Если в своем случае вы не получаете 5 «Нет» на 5 вопросов, это провал, и вы не можете достоверно сказать, что именно установило исследование: фактор ранжирования или фатальный побочный эффект употребления сыра.
Аналогичный процесс должен применяться по отношению к тематическим исследованиям, которые являются ещё одной формой корреляции — корреляцией между изменением и чем-то хорошим (или плохим), что произошло после. К примеру, задайтесь следующими вопросами:
- Исключил ли я другие факторы (например, внешний спрос, сезонность, делающих ошибки конкурентов)?
- Было ли увеличение трафика связано с моими действиями или же я случайно улучшил один из других факторов ранжирования?
- Сработало ли это благодаря уникальным обстоятельствам конкретного клиента/проекта?
Для SEO-специалистов это будет особенно сложно, поскольку они редко располагают данными такого качества. Задайте себе еще два вопроса, которые помогут вам сориентироваться в этом «минном поле»:
- Если бы я был Google, я бы сделал это?
- Если бы я был Google, мог бы я сделать это?
Прямой трафик как фактор ранжирования проходит тест «мог бы», но с трудом: Google мог бы использовать данные из Chrome, Android или от интернет-провайдеров, но они были бы отрывочны. Тест «я бы» этот вывод не проходит, так как для Google было бы намного проще использовать брендовый поисковый трафик.
2. Отсутствие контекста
Если бы кто-то сказал вам, что за неделю его трафик вырос на 20%, что бы вы сказали?
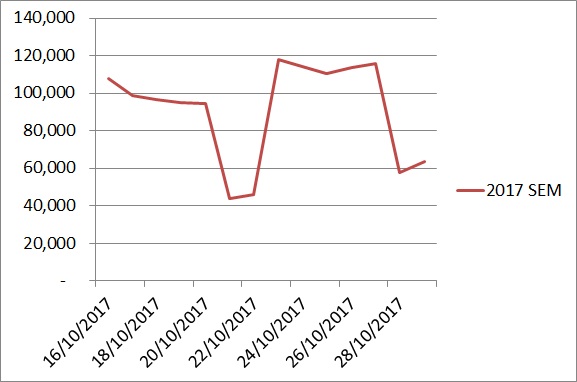
А что, если он вырос на 20% по сравнению с аналогичным периодом прошлого года?
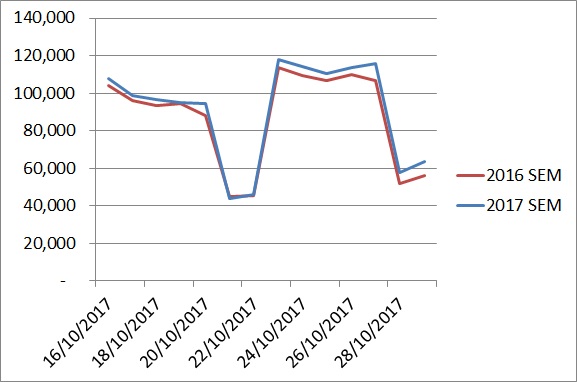
А что, если бы этот кто-то сказал вам, что до недавнего времени рост составлял 20% в годовом сравнении?
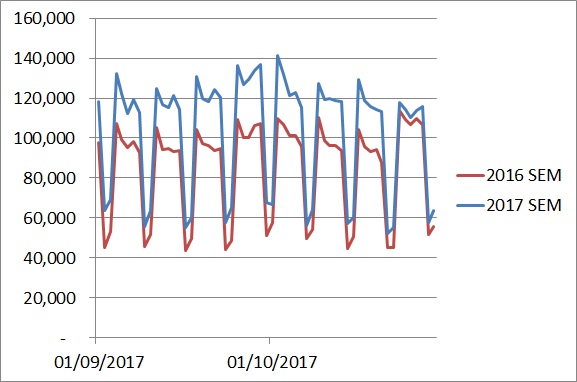
Забавно, как привнесение контекста может влиять на восприятие ситуации. Это еще одна проблема тематических исследований и их «злого брата-близнеца» — анализа падений трафика.
Если вы действительно хотите понять, стоит ли удивляться чему-либо — как в положительном, так и в отрицательном смысле — вам нужно сравнить это с вашими ожиданиями и затем выяснить, какое отклонение от этих ожиданий является «нормальным». В этом и заключается статистический подход.
Если вы не хотите лишний раз напрягаться, вам следует сделать шаг назад и добавить данные за предыдущие годы. Если кто-то показывает вам слишком акцентированные сведения, на них нужно полагаться с некоторой долей сомнения.
3. Доверие к аналитическим инструментам
Вы бы приняли многомиллионное бизнес-решение на основе данных, которыми ваш конкурент может манипулировать, как захочет? Вполне вероятно, что вы уже делаете это, а сами цифры можно найти в Google Analytics. Большинство аналитических платформ имеют ряд общих проблем:
- Ими легко манипулировать извне;
- Они произвольно группируют обращения в сессии;
- Они уязвимы для блокировщиков рекламы;
- Они работают с сэмплированием и проводят его открыто.
К примеру, знаете ли вы, что Google Analytics API v3 может активно сэмплировать данные, если объём трафика превышает определённый уровень (около 500 тысяч посещений), при этом сообщая вам, что данные не являются сэмплированными?
Подобные проблемы свойственны и многим другим инструментам «поисковой аналитики». Известно ли вам, что большинство платформ для отслеживания позиций в поисковике предоставляют совершенно разные результаты? Или как насчёт того, что ключевые слова, сгруппированные Google (и, соответственно, такими инструментами, как SEMRush и STAT), не являются эквивалентными и необязательно имеют указанные объёмы поиска?
Вы должны понимать сильные и слабые стороны сервисов, которыми пользуетесь, и знать, какие из предоставляемых ими данных стремятся к точности (и ведут вас в верном направлении), даже если они не идеально точны. Здесь вам остается только повышать свою квалификацию. «Прокачивая» знания по поисковой оптимизации (или любому другому digital-каналу), вы сможете разобраться в механизмах, стоящих за работой измерительных платформ.
Одно из самых распространенных решений этой проблемы заключается в использовании нескольких источников данных, но в этом подходе также есть свои минусы.
4. Комбинирование источников данных
Существует множество платформ, которые объединяют данные двух и более сервисов:
- Google Analytics;
- Google Search Console;
- AdWords;
- Rank Tracking.
Загвоздка состоит в том, что во-первых, у перечисленных платформ нет эквивалентных определений, а во-вторых, мы получаем такую графу, как «not provided».
Что касается определений, давайте рассмотрим посадочную страницу:
- В Search Console предоставляются данные о переходах, которые могут сэмплироваться при комбинировании нескольких измерений (например, ключевое слово и страница) или фильтров.
- В Google Analytics сообщается о последнем непрямом клике. При этом подразумевается, что органический трафик включает прямые сессии, тайм-ауты и т. д.
- В AdWords большинство отчётов основаны на данных о последнем клике, а конверсии могут определяться по-разному. Кроме того, объёмы поиска по ключевым словам могут объединяться, как уже указывалось выше.
- Rank Tracking ориентируется на местоположение и является непоследовательным.
По поводу «not provided»: большинство лендингов получают трафик по более чем одному ключевому слову. Очень вероятно, что некоторые из этих слов конвертируются лучше, чем другие. Это значит, что даже самая продуманная CTR-модель вам не поможет. Так как же узнать, какие ключевые слова являются ценными?
Лучше всего — провести обобщение, опираясь на данные AdWords, но маловероятно, что у вас есть данные по всем комбинациям ключевых слов и посадочной страницы. По сути, инструменты, предоставляющие такую отчётность, делают очень смелое предположение о том, что эта страница конвертируется одинаково по всем ключевым словам. В то же время некоторые сервисы занимают более открытую позицию в этом плане.
Опять же, это вовсе не значит, что такие инструменты бесполезны — вы просто должны понимать их ограничения и подходить к анализу данных как можно более вдумчиво. Единственный способ заполнить пробелы, создаваемые «not provided» — потратить кучу денег на поисковую рекламу, чтобы получить оценки объёма, коэффициента конверсии и показателя отказов по всем ключевым словам. Но даже это не поможет вам избавиться от терминологического несоответствия.
Бонусная метрика «Средняя позиция» (Average rank)
Чтобы понять, нужна ли вам эта метрика, рассмотрите 3 вопроса:
- О чём вы больше беспокоитесь: о потере ранжирования по десяти низкочастотным запросам (10 запросов в месяц и меньше) или же по одному высокочастотному запросу (миллионы запросов)? Если вы переживаете за НЧ-запросы, тогда этот показатель не для вас, и вам нужно использовать метрику видимости (visibility), основанную на оценочном CTR.
- Когда вы начинаете ранжироваться в топ-100 по ключевому слову, по которому раньше не ранжировались, вы расстраиваетесь? Если ответ «Да», значит эта метрика не для вас, поскольку в данном случае это приведёт к снижению вашей средней позиции. Используйте метрику видимости.
- Нравится ли вам сравнивать свои результаты с результатами конкурентов? Если ответ «Нет», то эта метрика не для вас. У ваших конкурентов может быть больше или меньше брендовых ключевых слов или long-tail позиций, и это будет искажать сравнение. И снова-таки, используйте метрику видимости.
Вместо заключения
- Подходите к анализу корреляционных и тематических исследований критически и проверяйте, можете ли вы объяснить их результаты через совпадение, обратную причинность, совместную причинность, линейность или нишевую применимость.
- Не анализируйте изменения в трафике без учёта контекста.
- Помните, что измерительные инструменты имеют ограничения, и следите за тем, как это влияет на предоставляемые ими данные.
- Комбинируя данные из нескольких инструментов, разберитесь в связях между ними и расценивайте полученную с их помощью информацию как направляющую, а не точную.
Делайте бизнес на основе данных!
По материалам: moz.com.





")








