



Представьте, что перед вами стоит задача найти все ключевые слова в большом отрывке текста: как вы это сделаете? Компания Priceonomics, сервис по сбору и анализу данных для бизнеса, разработала для этих целей собственное приложение. После ввода URL страницы в соответствующее окно краулера, «аналитическая машина» Priceonomics Analysis Engine с легкостью находит все ключевые слова, обращаясь при этом к простейшей функции.
Обычно, подобные скрипты по анализу текста в сети основаны на принципе поиска наиболее часто встречающихся слов. Однако, такой подход малоэффективен — он не позволяет отделить по-настоящему ключевые слова от большого числа служебных слов и местоимений, таких как «и», «например», «бы», «что» и т.д.
Другим направлением работы может стать сравнение исходного текста с текстами более общих тематик и выявление наиболее необычных слов и их повторений. Так, в этой статье специфические термины «кластер» или «массив» встречаются хоть и редко, но намного чаще, чем среди остальных статей блога, что говорит об их важном, ключевом характере. Проблема данной методики заключается в том, что для ее осуществления требуется значительный объем данных для сравнения, а он не всегда доступен, если конечно вы не гигантская корпорация.
«Search inside!» компании Amazon
В качестве иллюстрации семантического анализа через сравнение текстов, рассмотрим инструмент «Search inside!», который компания Amazon использует для обнаружения наиболее «Статистически невероятных слов» (SIP, Statistically improbable phrases) в своих книгах. В процессе сравнения участвуют абсолютно все когда-либо оцифрованные Amazon тексты, и в результате алгоритм помогает найти редкие слова в любой книге:
«Например, для книги о налогах нормально, что все ее SIP будут связаны с налогами. Однако, поскольку механизм располагает все редкие слова в порядке уменьшения их уникальности (сначала — самые уникальные), наверху списка окажутся те SIP, которые в данной конкретной книге встречаются чаще, чем в других книгах о налогах. Что касается художественной литературы, SIP имеют тенденцию выявлять важные словесные комбинации и элементы сюжета».
Amazon имеет возможность проводить такой анализ благодаря своей обширной и разнообразной базе информации — электронным книгам. Эти данные являются собственностью компании, а это означает, что такой инструмент анализа недоступен для большинства разработчиков. Даже если у вас имеется в наличии достаточное количество текстов, результаты поискового алгоритма могут оказаться нерелевантными, и для их коррекции все равно потребуется участие человека. Также сложность представляют тексты на иностранных языках, для анализа которых нужна отдельная база.
Priceonomics Analysis Engine
В связи с этим, Priceonomics задалась целью разработать свой собственный, быстрый и удобный алгоритм поиска ключевых слов a priori — без необходимости дополнительной подготовки или сбора информации об анализируемом тексте. Большинство известных методов не соответствовало этим критериям, но внимание разработчиков привлекла одна статья: «Уровневая статистика: анализ ключевых слов в литературных текстах и символьных последовательностях» («Level statistics of words: Finding keywords in literary texts and symbolic sequences» by Carpena et al. in 2009). Изучив изложенные в ней тезисы, специалисты сразу же приступили к их реализации.
Суть статьи заключалась в следующем: в любом тексте часто используемые, но не имеющие никакого значения слова распределяются в случайном порядке, тогда как важные, ключевые понятия имеют тенденцию объединяться в кластеры (clusters, скопления) или упорядоченные паттерны. Идея о кластерах была заимствована авторами из квантовой механики*, что навело их на мысль об анализе ключевых слов в текста[ по аналогии с энергетическим спектром.
*В физике под кластерами понимаются различные компактные структуры, состоящие из двух или большего числа частиц, которые могут возникать внутри атомного ядра.
Представив исходный текст как массив неупорядоченных данных, а затем создав для каждого слова свою «спектральную диаграмму», можно получить наглядную иллюстрацию их распределения в тексте.
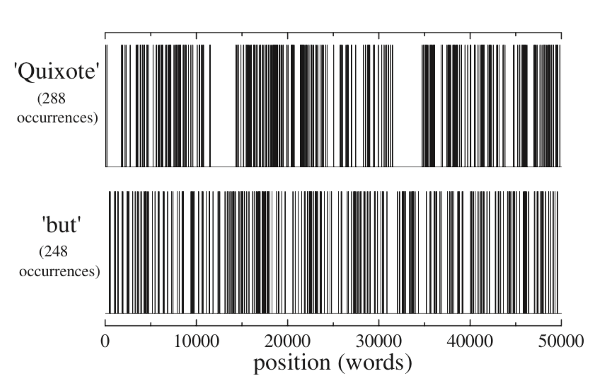
На изображении выше показан результат анализа первых 50 000 слов романа «Дон Кихот» (Don Quixote) Сервантеса. Хотя английский союз but («но») встречается в тексте почти так же часто (248 повторений), как и ключевое слово Quixote (288 повторений), паттерны их распределения отличаются.
Анализируя интервалы этого спектра, можно увидеть, что второстепенные слова распределяются хаотично, а значимые, наоборот, объединяются в группы. Именно частота повторения слов в совокупности с характером их распределения приводит к выводу об их релевантности: ключевыми окажутся лишь те слова, которые не только многократно встречаются в тексте, но и объединяются в четкие, компактные кластеры.
Однако, и этот алгоритм имеет свои недостатки. Анализ коротких текстов не может быть настолько же эффективным по сравнению с длинными: если источник содержит всего пару сотен слов, даже важные понятия могут встретиться только 2 или 3 раза, что даст довольно разреженный и не очень информативный спектр.
Также, метод не отличается гибкостью: если раньше вы могли не согласиться с результатами анализа и самостоятельно выбрать из полного списка найденных ключевых слов релевантные, то тут у вас нет такой возможности. Увеличение или уменьшение количества текстов для сравнения тоже не сработает — данный алгоритм предназначен только для одного источника.
Но так или иначе, основной «костяк» ключевых слов Priceonomics Analysis Engine вам выделит, причем довольно успешно. Вот наглядный пример:
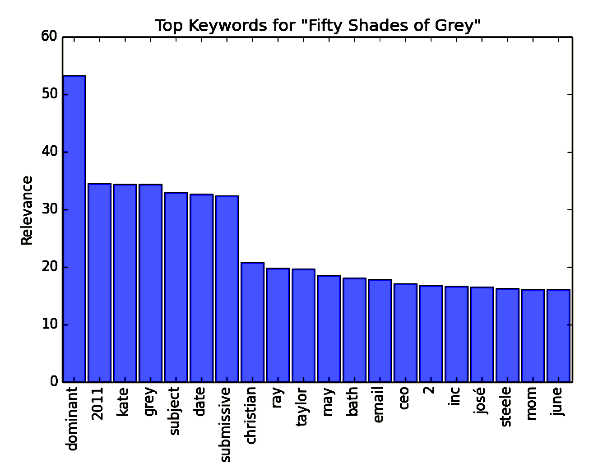
Топ ключевых слов книги «50 оттенков серого» Э. Л. Джеймс (слева направо, по уменьшению значимости): доминант, 2011, Кейт, Грей, тема, свидание, сабмиссив, Кристиан, Рэй, Тэйлор, может, ванная, сообщение/email, генеральный директор, 2, энтерпрайзес, Хосе, Стил, мама, июня.
Данный автоматический анализ был произведен Priceonomics в приложении Keywords. Вы тоже можете испытать новый алгоритм, чтобы проверить свой или чужой текст на ключевые слова. Однако, учитывайте, что из-за статистического характера методики, анализ производится эффективнее в текстах большой и средней длины.
Высоких вам конверсий!
По материалам priceonomics.comimage source terryhancock

















