


В последнее время искусственные нейронные сети показывают небывалый прогресс в области классификации изображений и распознавания речи. Этот полезный инструмент основан на известных математических законах, но на самом деле о работе его отдельных моделей мы знаем катастрофически мало.
Поэтому в сегодняшней статье постараемся рассмотреть несколько простых методик, позволяющих взглянуть на эти сети более подробно.
Современные нейросети: инсепшионизм и интерпретации
Сотрудники исследовательского отдела компании Google «тренируют» нейросеть, демонстрируя ей миллионы обучающих примеров и настраивая ее параметры до тех пор, пока классификация их не устроит. Как правило, сеть состоит из 10 — 30 слоев нейронов. Каждое изображение поступает в исходный слой, который взаимодействует с оставшимися слоями, вплоть до финального. Итоговый «ответ» сети мы получаем из последнего слоя.
Одна из основных проблем технологии заключается в понимании того, что происходит на каждом уровне. Нам известно лишь то, что после подготовки сеть начинает постепенно распознавать особенности изображения, пока последний слой не примет решение о содержимом картинки.
К примеру, начальные уровни могут распознавать грани или углы объектов. На средних уровнях полученные данные обрабатываются, чтобы определить общие формы и компоненты рисунка, будь то дверь или листок. Последние несколько слоев интерпретируют собранную информацию и делают выводы — эти нейроны реагируют на очень сложные объекты такие, как целое здание или деревья.
Чтобы понять принципы работы данной сети, к ней необходимо применить реверсивный подход — нейроны нужно настроить таким образом, чтобы они улучшали изображение до возникновения определенной интерпретации. Скажем, вы хотите узнать, какие рисунки могут превратиться в картинку с бананом. В таком случае вам нужно загрузить в сеть изображение с обычными помехами и адаптировать его под то, что нейросеть считает бананом.

И вот первый сюрприз: нейронные сети, обученные распознавать различные виды изображений, крайне ограничены в информации, которая нужна для создания картинок. Ознакомьтесь еще с несколькими примерами по разным классам:

Почему это важно? По словам представителей Google, сети демонстрируется множество примеров, чтобы она научилась отличать суть вещей (то есть, вилка состоит из ручки и 2 — 4 зубцов) от бесполезной информации (вилка может обладать любой формой, цветом или размерами). Но как понять, что система действительно освоила наиболее важные особенности объекта? При помощи абстрактных рисунков.
На самом деле, данная методика показывает, что в некоторых случаях сеть ищет не совсем то, что мы имеем в виду. К примеру, вот как одна из разработанных моделей видела обыкновенные гантели:

На картинках действительно показаны гантели, однако все эти изображения кажутся незавершенными. В данном случае нейросеть неверно распознала суть рассматриваемого объекта. Возможно, это связано с тем, что ей всегда демонстрировали гантели в руке тяжелоатлета. Как бы там ни было, визуализация может помочь избавиться от подобных учебных просчетов.
Указывать желаемые особенности для каждой новой интерпретации необязательно — это решение можно доверить и самой системе. В таком случае, нужно загрузить в сеть произвольное изображение и подождать, пока она его проанализирует. Затем выбрать слой и попросить систему улучшить все элементы, которая она зафиксировала. Каждому слою нейронов соответствует определенный уровень абстракции, поэтому сложность итоговой графики будет зависеть от нашего выбора.
К примеру, нижние слои обычно генерируют штрихи и простые орнаменты, потому что они реагируют на базовые особенности объектов, такие как грани и их направляющие.
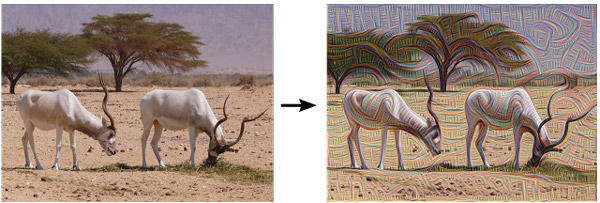

На высоких уровнях, которые распознают более изощренные детали изображения, возникают сложные очертания или даже целые объекты. Опять-таки, мы просто берем реальный снимок, загружаем его в нейросеть и говорим системе: «Что бы ты там ни увидела, сделай этого больше!».
Таким образом возникает петля обратной связи (feedback loop): если облако будет немного похоже на птицу, сеть приблизит его к данному образу. На последующих уровнях этот эффект будет постепенно усиливаться, пока на изображении не появится подробно прорисованная птица, практически из ниоткуда.

Пока что результаты весьма интригующие — даже относительно простую нейронную сеть можно использовать для интерпретации картинок. В данном случае сеть обучали при помощи изображений с животными, поэтому все формы она пытается преобразовывать в зверей. Но поскольку все сохраненные данные абстрактны, в итоге мы получаем вот такие интересные миксы:

Конечно же, при помощи этой методики можно изменять не только облака, но и любые другие объекты. При этом результаты будут отличаться от исходного изображения, так как изученные особенности направляют сеть в сторону определенной интерпретации. К примеру, линии горизонта чаще всего заменяются башнями и пагодами. Скалы и деревья превращаются в здания. Листья порождают птиц и насекомых.

Эта техника дает представление об уровне абстракции, которого достиг каждый слой нейронов в понимании образов. Сотрудники Google назвали данную методику «инсепшионизмом» (inseptionism) в соответствии с архитектурой, которая используется нейронной сетью.
При многократном задействовании данного алгоритма и масштабировании каждой итерации мы получаем нескончаемый поток образов, охватывающий все знания нейронной сети. Начинать этот процесс можно практически с любого снимка — в результате система все равно предоставит вам уникальное изображение:

Вместо заключения
Представленные здесь техники помогают понять, как именно нейросети справляются со сложными классификационными задачами, а также позволяют улучшить сетевую архитектуру и проверить, чему система научилась во время подготовки.
Как знать, возможно в будущем нейронные сети станут полноценным художественным инструментом или даже прольют немного света на саму суть творческого процесса и восприятия произведений искусства.
По материалам: googleresearch.blogspot.co.uk, Image source: Birth Into Being


?")












