


Боб Мур (Bob Moore), соучредитель и генеральный директор SaaS-компании кросс-платформенной аналитики RJMetrics, выступил на ежегодной конференции Habit Summit в 2016 году с презентацией о том, как выявлять и формировать пользовательские привычки, используя data-driven подход.
Вступление
В начале 1980-х гг. память продавалась по цене 2 цента за байт. На первый взгляд, кажется, что это не так уж и много. Но так кажется ровно до тех пор, пока мы не вдумаемся, что же такое байт в действительности.
Так, владельцу небольшой кофейни, чтобы сохранить необходимую информацию о продаже чашки кофе в базе данных (дата и время продажи, наименование, стоимость, и т.д.) потребовалось бы примерно 16 байт или 32 цента. Учитывая, что средняя стоимость чашки кофе в то время была около 50 центов, сохранение всех этих данных было абсолютно невыгодным в экономическом плане.
Подумать только, 1 Гб при тех расценках стоил $20 000 000!
 Не так давно….
Не так давно….К счастью, ситуация с тех пор существенно изменилась, и стоимость хранения данных резко снизилась. Сейчас вы можете приобрести флешку на 1 Гб примерно за $0.80 вместо $20 000 000. Ее хватит, чтобы сохранить информацию о продаже 62 500 000 чашек кофе.
Кроме этого произошел фундаментальный сдвиг в возможностях передачи, хранении и сбора данных. На графике ниже отображен рост скорости передачи данных за период с 1970 по 2012 гг.:

Скорость передачи данных в домашней сети, 1970-2012 гг.
Шкала по вертикали: скорость (бит в секунду)
Шкала по горизонтали: год
Некоторые из вас, возможно, знакомы со следующей инфографикой. Это ландшафт маркетинговых технологий по состоянию на август 2011 и март 2016 года:

 Ландшафт маркетинговых технологий в 2011 и 2016
Ландшафт маркетинговых технологий в 2011 и 2016 В 2011 году на этой инфографике было 100 компаний, в то время как в 2016 их насчитывалось уже 1 876. Каждая из этих технологий позволяет использовать интернет для сбора информации о людях, взаимодействующих с продуктами компаний. Это источники данных (data sources) возникли потому, что сегодня хранение данных стоит дешево, а скорость ее передачи колоссальная.
Возможность сохранять всю необходимую информацию о продукте и пользователях позволяет иметь достаточное количество данных о поведении ваших клиентов, чтобы начать анализировать их действия с точки зрения психологии.
Сейчас проще, чем когда-либо понимать поведение и привычки своих клиентов, используя data-driven подход. Именно об этом и пойдет речь в этой статье.
Корреляция и причинность
Очень часто происходит подмена понятий «корреляции» (correlation) и «причинности» (causation).
Основная идея здесь такова: только потому, что две вещи ведут себя сходным образом, еще не означает, что одна из них вызывает другую.
Тайлер Вигэн (Tyler Vigen), автор блога Spurious Correlations (Ложные корреляции), находит корреляции между совершенно несвязанными между собой статистическими данными. Например, между количеством смертей в бассейнах и количеством фильмов с участием Николаса Кейджа. Его цель — показать, что наличие корреляции нельзя приравнивать к наличию причинно-следственной связи.
 Количество людей, утонувших в бассейне (коричневый график) коррелирует с количеством фильмов с Николасом Кейджем (черный график)
Количество людей, утонувших в бассейне (коричневый график) коррелирует с количеством фильмов с Николасом Кейджем (черный график)Взглянув на график, можно сказать, что существует серьезная связь между двумя этими величинами. Наш мозг приходит к умозаключению, что каким-то образом Николас Кейдж ответственен за эти смерти.
Объяснений, почему это действительно может быть так, — множество. Вот лишь некоторые из них:
- Прямая причинно-следственная связь: фильмы с Николасом Кейджем вызывают смерти в бассейнах. Возможно, фильмы с его участием настолько дезориентируют людей, что те в буквальном смысле падают в бассейн и тонут.
- Обратная причинно-следственная связь: смерти в бассейнах влекут за собой появление фильмов с Николасом Кейджем. Возможно, люди, связанные с индустрией бассейнов, каждый раз, когда происходит возрастание смертностей в результате утопления в бассейнах, хотят отвлечь внимание общественности от этого факта и способствуют выпуску фильмов с Николасом Кейджем.
- Скрытая переменная: существует третья переменная, вызывающая оба этих события. Допустим, когда ожидается жаркое лето, в прокат выпускают больше блокбастеров, а люди чаще проводят время в бассейнах. Либо происходит экономический спад, и Николас Кейдж больше склонен сниматься в этот период период, а люди больше времени проводят дома, отдыхая у своих бассейнов.
- Циклическая причинность. Это теория, согласно которой Николас Кейдж — серийный убийца. Каждый раз, когда выходит фильм с его участием, он испытывает столь сильную эйфорию, что начинает ходить и сталкивать людей в бассейны. Но только в тот момент, когда он сталкивает кого-то в бассейн, к нему и приходят идеи хороших фильмов. Таким образом, А вызывает В, а В вызывает А.
- Эти вещи совершенно не связаны между собой.
Цель этого примера состоит не в том, чтобы сказать, что единственное верное объяснение — последнее, а дать понять, что мы на самом деле не знаем правды. И без сбора дополнительной информации мы не сможем сделать этого, так как каждая из этих вещей теоретически возможна.
Для получения желаемых результатов мы должны использовать данные корреляции в качестве направляющих указателей, способных привести нас к дополнительным тестам и возможности выполнения итераций, используя цикл проверки гипотез «создать-оценить-научиться» (Build, Measure, Learn):
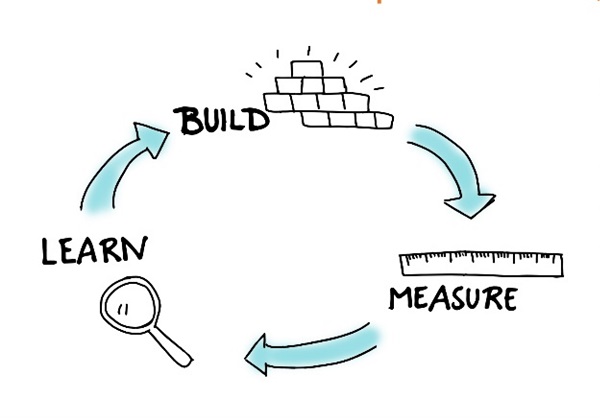 Цикл проверки гипотез «создать-оценить-научиться» (Build, Measure, Learn)
Цикл проверки гипотез «создать-оценить-научиться» (Build, Measure, Learn)Итеративный процесс, основанный на данных, позволяет найти настоящие результаты, даже с учетом ошибочно-позитивных результатов (false positives).
Статистическая значимость
Скажем, вы решили провести сплит-тестирование на вашем сайте, и ваш текущий коэффициент конверсии (conversion rate) составляет 1%.
Вы тестируете другую версию страницы, и коэффициент конверсии возрастает до 1.1% (эксперимент А). В этом случае для достижения статистически значимых результатов вам потребуется 159 650 посетителей.
В эксперименте B мы переходим от 1% к 2%, и размер необходимого трафика резко снижается до 2 226 посетителей.

Если провести эксперимент, в результате которого коэффициент конверсии увеличится до 3%, количество необходимого трафика снизится еще существеннее.
Что касается стартапов, то у них нет возможности иметь огромные размеры выборки, чтобы узнать какие-то вещи о своих продуктах и о том, как клиенты могут конвертироваться или взаимодействовать с ними. Вы действительно должны играть по-крупному. В противном случае можно умереть в ожидании, потому что вы окажетесь в ситуации, когда постепенные по своей природе изменения не могут быть протестированы за тот период времени, которым вы располагаете. И в большинстве случаев при таком сценарии вы будете достигать локальных максимумов (local max).
Таким образом, совершая небольшие постепенные изменения (цвета кнопки, текст на домашней странице, и т.д.), вы вероятно начнете с A, дойдете до локального максимума, а затем проведете еще один тест и перейдете в точку B. В этот момент вы подумаете: «Что ж, в этом направлении график идет вниз, как и в другом. Я нашел свой максимум». Тестируя небольшие постепенные изменения, вы так и не обнаружите свой глобальный максимум (big max).
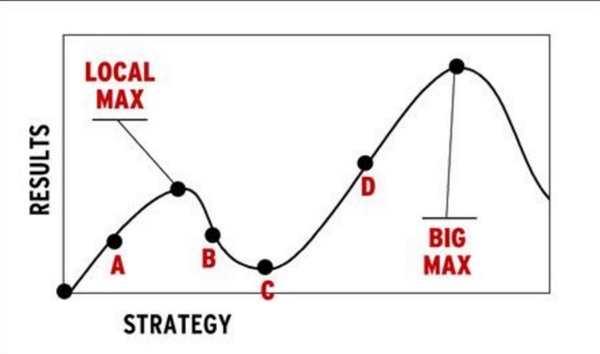
Шкала по вертикали: результаты
Шкала по горизонтали: стратегия
Если у вас очень ограниченное количество данных и вы хотите быть уверенным в том, что вы обнаружите свой глобальный максимум, самое важное, что вы должны сделать — это тестировать крупные изменения.
Большие изменения позволяют вам не только получить ответы гораздо быстрее (так как в этом случае влияние на коэффициент конверсии совсем другое), но также найти эти глобальные максимумы.
Далее мы рассмотрим некоторые примеры реальных техник, которые использовали RJMetrics.
Техника: «анализ золотых движений» (Golden Motion Analysis)
За этим броским названием в действительности скрывается не что иное как ретроспективный анализ (retroactive analysis) поведения пользователей, способный предсказывать вероятность совершения ими желаемого действия в будущем.
Рассмотрим его применение на конкретном примере.
Компания RJMetrics предлагает всем желающим бесплатную пробную версию своего продукта (инструмент бизнес-аналитики). В течение 7 дней пользователи могут протестировать все его функции.
Компания решила выяснить, какие действия людей ведут к увеличению коэффициента конверсии, и затем, используя эту информацию, изменить свой onboarding-процесс таким образом, чтобы большее количество пользователей совершали эти действия.
С этой целью они решили вооружить свой продукт инструментом, который бы собирал различные данные. Еще несколько лет назад сделать подобное было бы очень сложно. Сейчас же благодаря тому, что появилось огромное количество SAS-инструментов (например, Mixpanel, Snowplow, Heap), можно легко собирать подробную информацию обо всем, что происходит с вашим продуктом:
- Вход в систему
- Создание графиков
- Редактирование графиков
- Добавление пользователей
- Предоставление общего доступа к панелям мониторинга
- Использование API
- Подключение нескольких источников данных
- Время, проведенное в инструменте
Далее вы должны просто соединить полученную информацию с другими значимыми данными, касающихся ваших целей. Для RJMetrics этой целью было увеличение коэффициента конверсии. Здесь вы опять же можете использовать инструменты сторонних производителей, к примеру, тот же RJMetrics.
В итоге у вас образуется подобная таблица:
Каждая запись здесь отображает одно конкретное действие пользователя: создание таблицы, вход в систему, добавление нового пользователя, и т.д.
После этого вы можете свести все эти данные к истории о каждом отдельном пользователе, воспользовавшимся бесплатной версией вашего продукта.
В итоге компания могла сказать по каждому пользователю, конвертировался он или нет, сколько графиков он создал, сколько пользователей добавил, какое количество данных присоединил, использовал ли он API, и т.д. Всего у них было 20-30 разных параметров:
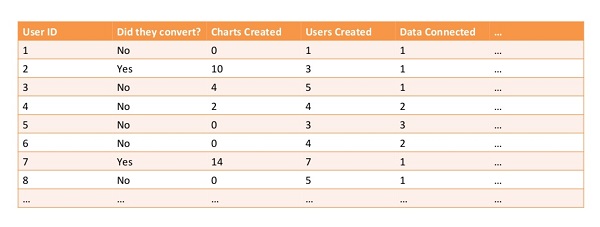
Слева-направо: ID пользователя, конвертировался он или нет, количество созданных графиков, количество добавленных пользователей, количество присоединенных данных, и т.д.
Затем они провели тесты для проверки гипотез, чтобы выяснить, вели ли те или иные действия пользователей к увеличению коэффициента конверсии.
У RJMetrics была куча теорий. К примеру, одна из них звучала так: присоединение большего количества источников данных ведет к увеличению коэффициента конверсии. И эта гипотеза оказалась ложной. Сравнив количество людей, добавивших один источник данных, с количеством тех, кто добавил более одного источника данных, они обнаружили отсутствие статистически значимого отличия и соответственно доказательства того, что данное действие пользователей ведет к увеличению конверсии:
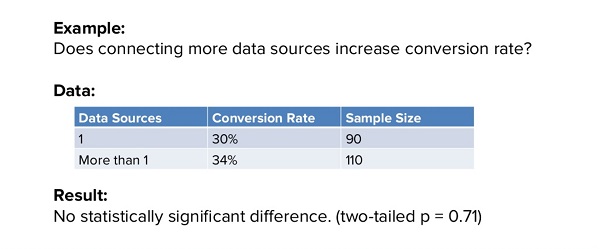
Они прошлись по всему списку предположений, пока не дошли до создания графиков. Вопрос был следующий: ведет ли создание большего количества графиков во время пробного периода к увеличению коэффициента конверсии? И ответом было решительное «да»:
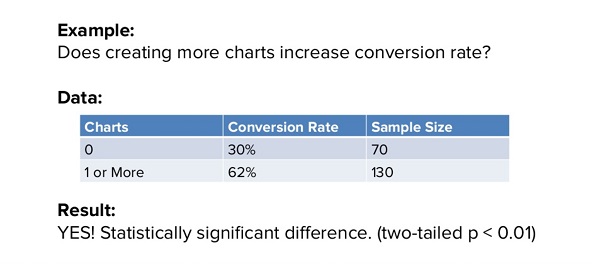
Из тех, кто не создал вообще ни одного графика, в итоге конвертировались только 30% людей. Из тех же, кто добавил 1 и более график, конвертировалось 62%.
Тест показал сильное статистически значимое отличие даже с довольно небольшим размером выборки (sample size).
Они пошли дальше и сравнили результаты по большему количеству графиков, и обнаружили каскадную статистическую значимость: чем больше графиков было создано, тем выше был коэффициент конверсии:
 Слева-направо: количество графиков, коэффициент конверсии, размер выборки, статистическая значимость (да/нет)
Слева-направо: количество графиков, коэффициент конверсии, размер выборки, статистическая значимость (да/нет)В итоге они изменили свой продукт таким образом, чтобы каждый пользователь создал по крайней мере 2 графика:
- Создали обучающий тур по использованию построителя отчетов (report builder).
- Давали новым клиентам домашние задания по созданию собственных отчетов. Улучшили документацию по построителю отчетов.
- Снабдили менеджеров по работе с клиентами инструментами для отслеживания этой метрики.
И затем им нужно было напомнить себе об «эффекте Николаса Кейджа». Только потому что люди создают графики и коэффициент конверсии увеличивается, еще не доказывает, что внесение всех этих изменений обязательно приведет к увеличению коэффициента конверсии. Возможно, пользователи, которые конвертировались, просто изначально были расположены к созданию графиков. В связи с этим было важно вернуться назад и повторно измерить данные, провести процесс еще раз и посмотреть, что произойдет.
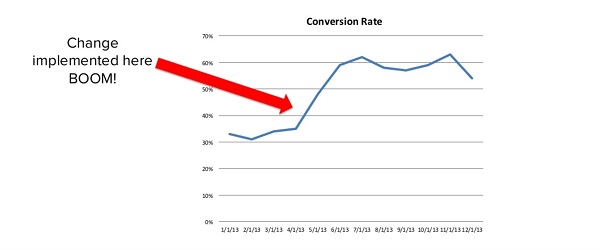 Рост коэффициента конверсии RJMetrics, 2013 г.
Рост коэффициента конверсии RJMetrics, 2013 г.В итоге за 2 месяца RJMetrics удалось увеличить свой коэффициент конверсии вдвое.
Если бы они просто проводили сплит-тестирования или пытались следовать своей интуиции без использования всех этих инструментов и измерения данных, они никогда бы не обнаружили, что именно создание графиков было тем действием, способным привести их к таким результатом. Это был очень значимый момент в истории компании.
Техника: Кластерный анализ (cluster analysis)
Зачастую мы думаем о наших потенциальных клиентах с точки зрения персон пользователя (user personas) или пользовательских групп (user group). Построение этих образов идеальных клиентов чрезвычайно важно для любой компании.
Исторически сложилось так, что огромное количество работы по созданию этих образов на самом деле осуществляется без использования фактических данных. Многие создают гипотетические образы пользователей, основываясь лишь на проведенных опросах, и т.д. Хотя это и очень эффективно, сегодня существует большое количество бесплатных технологий, позволяющих вам определить ваши персоны пользователя и поместить людей в эти группы.
Здесь снова пригодится та сводная таблица, которую мы рассматривали выше, поскольку она представляет собой перечень всех тех вещей, которые разные люди делают с продуктом. В случае с кластерным анализом вы можете определить параметры, по которым вы будете группировать людей:
Что касается RJmetrics, они всегда знали о 2 типах своих пользователей: один из которых был «зритель» (тот, кто использовал и просматривал графики), а другой — «создатель» (тот, кто создавал графики). Соответственно, если человек создал хотя бы один график, он попадал в категорию «создатель».
Результат проведенного ими кластерного анализа, в котором использовались всего 2 признака «просмотр отчетов» и «создание отчетов», вы можете видеть ниже:
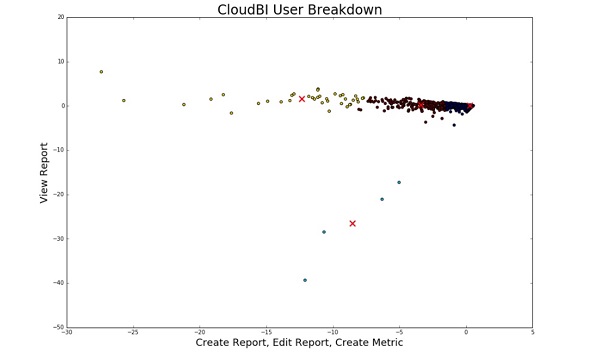
Шкала по вертикали: просмотр отчета
Шкала по горизонтали: создание отчета, редактирование отчета, создание метрики
4 красных X на этом графике соответствуют центрам кластеров — наиболее типичным представителям данного кластера.
Также, если вы заметили, точки на графике окрашены в разные цвета в соответствии с принадлежностью к одному из 4-х кластеров.
Обратите внимание на зеленые точки рядом с X в правом нижнем углу:
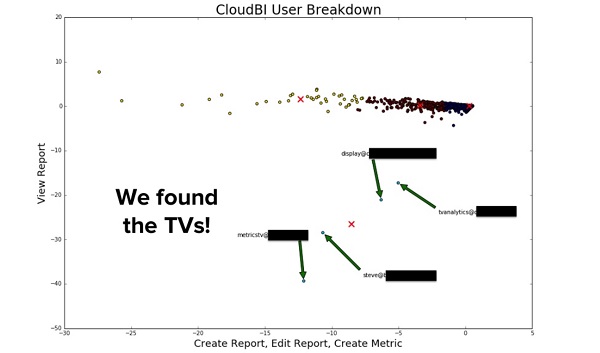
Эти люди были самыми «изголодавшимися» потребителями, которые так ничего и не создали. Они заходили в систему ежедневно и каждые 5-10 минут обновляли страницу. Кластерный анализ активно определял аккаунты этих клиентов.
Оказалось, были случаи, когда компании крепили телевизоры на стене, выводили на них панель RJMetrics и устанавливали расширение для браузера, автоматически обновляющее страницу каждые 10 минут.
Таким образом, RJMetrics обнаружили паттерн использования (usage pattern), о котором они даже не догадывались, но который демонстрировал большой объем потребления их продукта.
Далее они связались с этими компаниям, провели тематические исследования (case studies) по использованию их продукта в качестве платформы для визуального отображения информации, и создали контент по использованию продукта подобным образом.
Теперь перейдем к пользователям, находящимся в левом верхнем углу. Это те пользователи, которые взаимодействовали с панелью RJMetrics уже более реалистично, но так и не создали ни одного графика:
В большинстве случаев этими людьми оказывались генеральные директора и другие руководители; то есть люди, ответственные за потребление информации, но не являющиеся прямыми создателями этих данных.
Имея возможность математически определить, кто попадает в эту группу, а кто нет, RJmetrics смогли сказать, что важно именно для них. Так, для этих руководителей не важно, что компания обучает создавать графики — для них важно правильно трактовать данные.
И, наконец, самыми перспективными для компании были две оставшиеся группы пользователей:
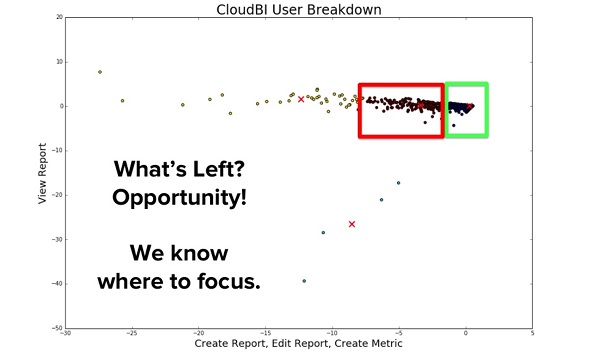
В зеленом квадрате находятся «супер-пользователи» RJMetrics. Это люди, которые создавали графики и взаимодействовали с ними; люди, которые очень часто входили в систему. Одним словом, это те пользователи, о которых все мы мечтаем.
Но также на графике мы видим красный прямоугольник — это люди, находящиеся на пороге того, чтобы стать этими «сверх-пользователями». У них имелись все необходимые навыки для создания графиков и они заходили в систему довольно регулярно. Однако они не потребляли продукт так же «жадно», как пользователи из зеленого квадрата.
У компании появилась возможность обратиться напрямую к этим пользователям и способствовать тому, чтобы со временем они перешли в разряд пользователей из зеленого квадрата. При этом они не тратят время руководителей и тех людей, кто уже и так находится в зеленом квадрате. Их, в свою очередь, они возможно будут склонять к получению тематических исследований или привлекать на пользовательские конференции, и т.д.
В результате, благодаря кластерам, которые они смогли определить, компании удается сохранять расположение своих пользователей и не вызывать у них чувства отторжения неинтересными для них сообщениями.
Вместо заключения
Таким образом, возможности, которые открывают для нас данные, безграничны. И в этом, собственно, и состоит мораль всей истории.
Очень важно, чтобы компании осознавали всю значимость и ценность данных. Хотя они и не ответят на все ваши вопросы, при всем при этом они представляют собой необычайно важный элемент, который становится все более значимым по мере того, как вы изучаете пользовательские привычки.
Делайте бизнес на основе данных!
По материалам: habitsummit.com

?")

 в маркетинге: проблемы, алгоритмы, методы анализа")









