



Голосовой и экранный типы взаимодействия сходятся в двух направлениях:
- Устройства, ориентированные в первую очередь на управление через экран (Screen-First), такие как смартфоны, планшеты и телевизоры, дополняются системами голосового управления.
- Управляемые голосом устройства (Voice-First), такие как смарт-колонки, усиливаются экранами, подобными Echo Show.
Несмотря на распространенные описания в научно-фантастических произведениях, не стоит ожидать, письменный ввод информации будет полностью заменен речевыми командами. Но ясно, однако, что стандартная коммуникация «человек-машина» быстро развивается, стремясь охватить как письменное, так и устное общение. В настоящее время голосовое взаимодействие в первую очередь входит в сферу личного и домашнего использования. Но по мере привыкания к нему люди начнут ожидать его появления и в деловых и коммерческих контекстах. (Те, кому когда-либо приходилось «биться» над неидеальной работой проектора в конференц-зале или над неудобным меню телефонной системы, представьте, что вы сможете просто сказать «Показать мой экран» или «Начать встречу» — и действие будет моментально совершено).
Полностью интегрированные системы «голос плюс экран» могут трансформировать пользовательский опыт (User Experience, UX) для огромного круга задач, используя сильные стороны каждого стиля взаимодействия:
- Голос — это эффективный механизм ввода (input): он позволяет пользователям быстро давать команды системе. Управление по громкой связи обеспечивает возможность многозадачности, а эффективная обработка на естественном языке лишает необходимости создания сложных навигационных меню, по крайней мере, для некоего набора знакомых задач и известных команд.
- Экран — это эффективный способ вывода информации (output): он позволяет системам одновременно отображать большой объем сведений и тем самым уменьшать нагрузку на память пользователей. Визуальное сканирование выполняется быстрее, чем последовательный доступ к информации, обеспечиваемый голосовым выводом. Экраны также способны эффективно передавать статус системы и выходить из ситуации «Пропасть выполнения» (Gulf of Execution — необходимость понимать, как инструмент помогает пользователю в достижении цели), предоставляя визуальные обозначения всевозможных команд.
Логично стремление объединить голос и экран. Но проблемы интеграции двух столь разных режимов взаимодействия в одном дизайне до сих пор не позволили полностью реализовать преимущества как голоса, так и экрана в какой-либо единой системе.
Ограничения взаимодействия в системах Screen-First
До недавнего времени большинство устройств, сочетающих управление экраном и голосом, соответствовали принципу Screen-First: это были смартфоны с системой голосового управления, которая дополняла уже существующий графический пользовательский интерфейс в качестве голосового агента (Siri или Google Assistant).
Подобные ориентированные на экранное управление системы демонстрируют впечатляющие способности в распознавании и обработке речи, но в целом пользовательский опыт остается сильно фрагментированным из-за фундаментального разделения между речевым агентом (Voice Agent) и функциональностью сенсорного экрана.
Отсутствие функциональности
Слишком часто речевой агент способен инициировать лишь первый шаг задачи, а любые последующие шаги требуют, чтобы пользователь переключился на взаимодействие с сенсорным экраном. Например, Siri выполнит запрос о поиске в Интернете или откроет приложение Apple News в ответ на голосовую команду, но затем для выбора результата поиска или получения доступа к новостям пользователю нужно будет коснуться экрана. Google Assistant также требует ввода информации на экране для того, чтобы продвинуться дальше при поиске.

И Siri, и Google Assistant могут выполнить голосовую команду по поиску рецепта, но затем требуется, чтобы пользователи коснулись экрана, выбрали результат и самостоятельно завершили задачу
Недостаточное использование экрана в режиме «Голос»
Даже для задач, имеющих определенную поддержку многоступенчатого голосового ввода, Siri использует дизайн экрана, полностью отличающийся от GUI-версии, и плохо использует доступное пространство экрана. Например, Siri способна читать текстовые сообщения и отправлять ответы. Но при чтении сообщения вслух экран остается темным, и появляется только имя отправителя, а не сам текст сообщения. Аналогично, при голосовом наборе ответа экран не отображает текст сообщения, на которое вы отвечаете, как это происходило бы в графическом интерфейсе пользователя (Graphical User Interface, GUI) приложения для обмена сообщениями. Происходит необоснованное ограничение информации, доступной пользователю. А ведь по идее устройство в голосовом режиме должно иметь возможность отображать больший объем истории переписки, поскольку в нем будет отсутствовать необходимость отображения клавиатуры.
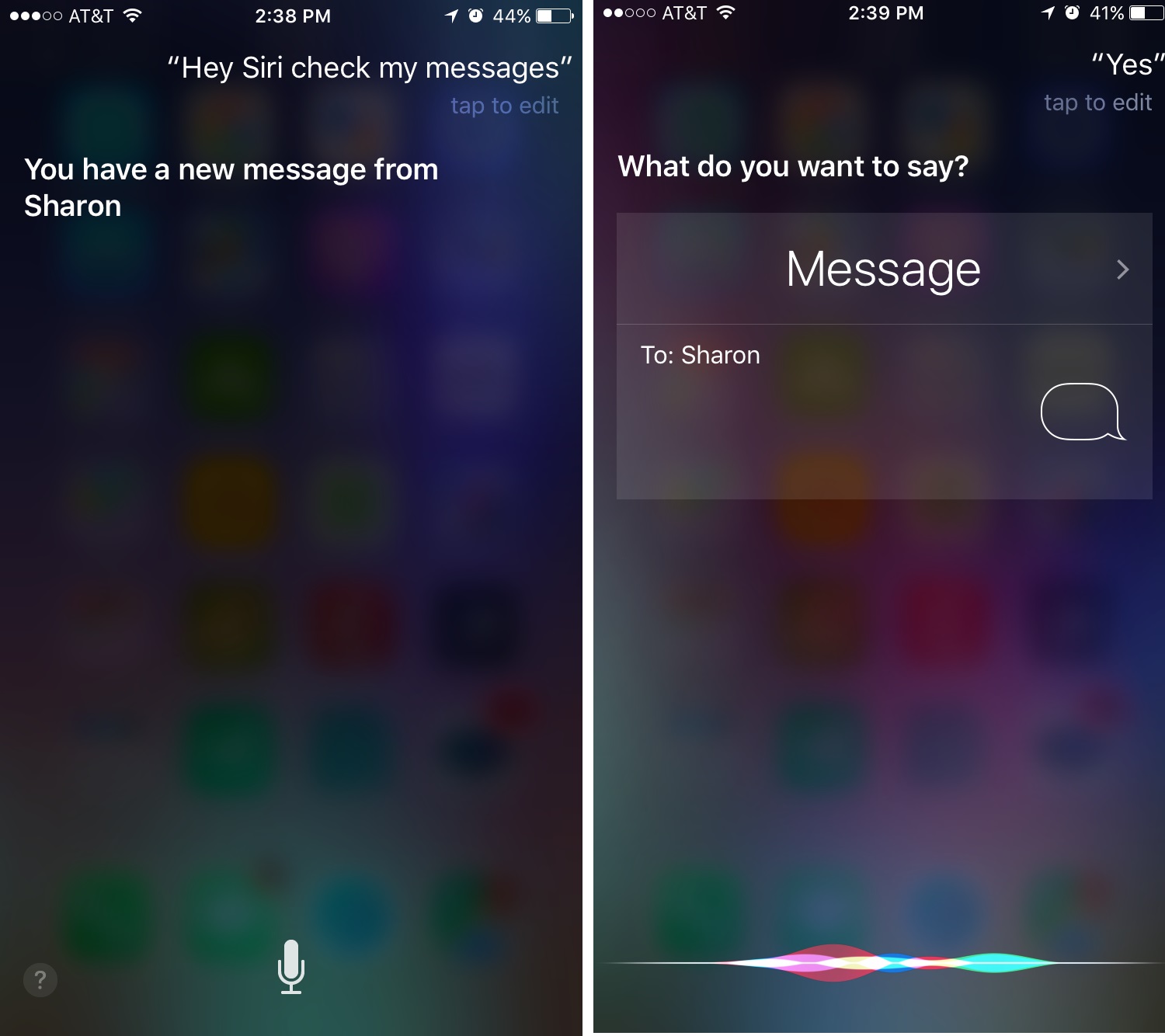
Siri читает текст вслух (слева), но содержимое полученного сообщения не отображается на экране, а во время диктовки ответа (справа), вам не видно сообщение, на которое вы отвечаете.
Сокрытие возможности действия
Минималистичный экран речевого агента Siri также лишен большинства визуальных преимуществ, имеющихся в графическом интерфейсе пользователя и позволяющих понять, например, что существует возможность редактирования текстового сообщения перед его отправкой. (Google Assistant имеет гораздо больше возможностей: он предлагает разные команды, отображая их под результатом задачи, а также выдает ленту (фид), позволяющую вернуться к предыдущим задачам.)
Взаимодействие только голосом
Радикально новый подход к голосовому взаимодействию появился с изобретением умных динамиков (Smart Speakers), таких как Echo от Amazon и Google Home. Эти устройства не имеют вообще никакого визуального отображения, и их повседневное использование полностью зависит от аудио, как для ввода, так и для вывода информации (у них имеется только несколько мигающих сигналов). Благодаря улучшению точности распознавания голоса на средних расстояниях, умные динамики обеспечивают возможность работы в режиме hands-free, что повышает гибкость и эффективность выполнения задач, а это, в свою очередь, делает данный продукт желанным даже для тех пользователей, у кого уже есть смартфон с поддержкой голосового ввода.
Серьезным ограничением для таких динамиков является отсутствие экрана. Чтобы дать пользователям понять, какие команды существуют, могут использоваться только звуковые сигналы, а прослушивание информации по сложным задачам может быть утомительно. Да, весьма удобно устанавливать таймер при приготовлении еды с помощью голосовой команды, но задача уточнения того, сколько времени осталось до конца готовки уже менее удобно. Прослушивание прогноза погоды становится для пользователя настоящим экзаменом, ведь он должен прослушать и попытаться запомнить ряд погодных данных на всю неделю, вместо того чтобы просто взглянуть на экран.
Взаимодействие Voice-First
Успех смарт-динамиков в сочетании с разочаровывающими ограничением в виде только голосового вывода информации породил новый продукт: Echo Show добавил к умному динамику Echo, работающему в качестве основного устройства, дисплей. Экран значительно расширяет функциональность исходного инструмента и упрощает задачи, такие как проверка погоды и мониторинг таймеров. Но по сравнению с экранными устройствами с полным графическим интерфейсом (например, их собственным планшетом Amazon Fire 7 по значительно более низкой цене) Echo Show гораздо менее способен выполнять базовые функции, уже давно доступные на смартфонах и планшетах. Например, данный гаджет даже не может (пока) просматривать сайты, показывать отзывы или отображать содержимое вашей корзины покупок в Amazon.
Что Echo Show действительно предлагает, так это в корне отличный от предыдущих стиль взаимодействия, который можно описать термином «Voice-First» и который почти целиком полагается на голосовой ввод, не отводя при этом речи ограниченную роль второго плана.
Взаимодействие Voice-First относится к системе, принимающей главным образом голосовой ввод пользовательских команд; аудиоввод информации дополняется высоко интегрированным экранным дисплеем.
Несмотря на то, что технически Echo Show представляет собой тачскрин, кнопки или меню появляются в нем редко. (Как бы нехотя на тачскрине появляется лишь клавиатура для ввода пароля, сразу же после этого действия исчезающая и никогда не появляющаяся вновь.)
Вместо того чтобы поощрять юзеров к нажиманию и перелистыванию, Echo Show часто отображает предлагаемые вербальные команды, например, такие: «Попробуйте сказать: Алекса, пролистни вправо».
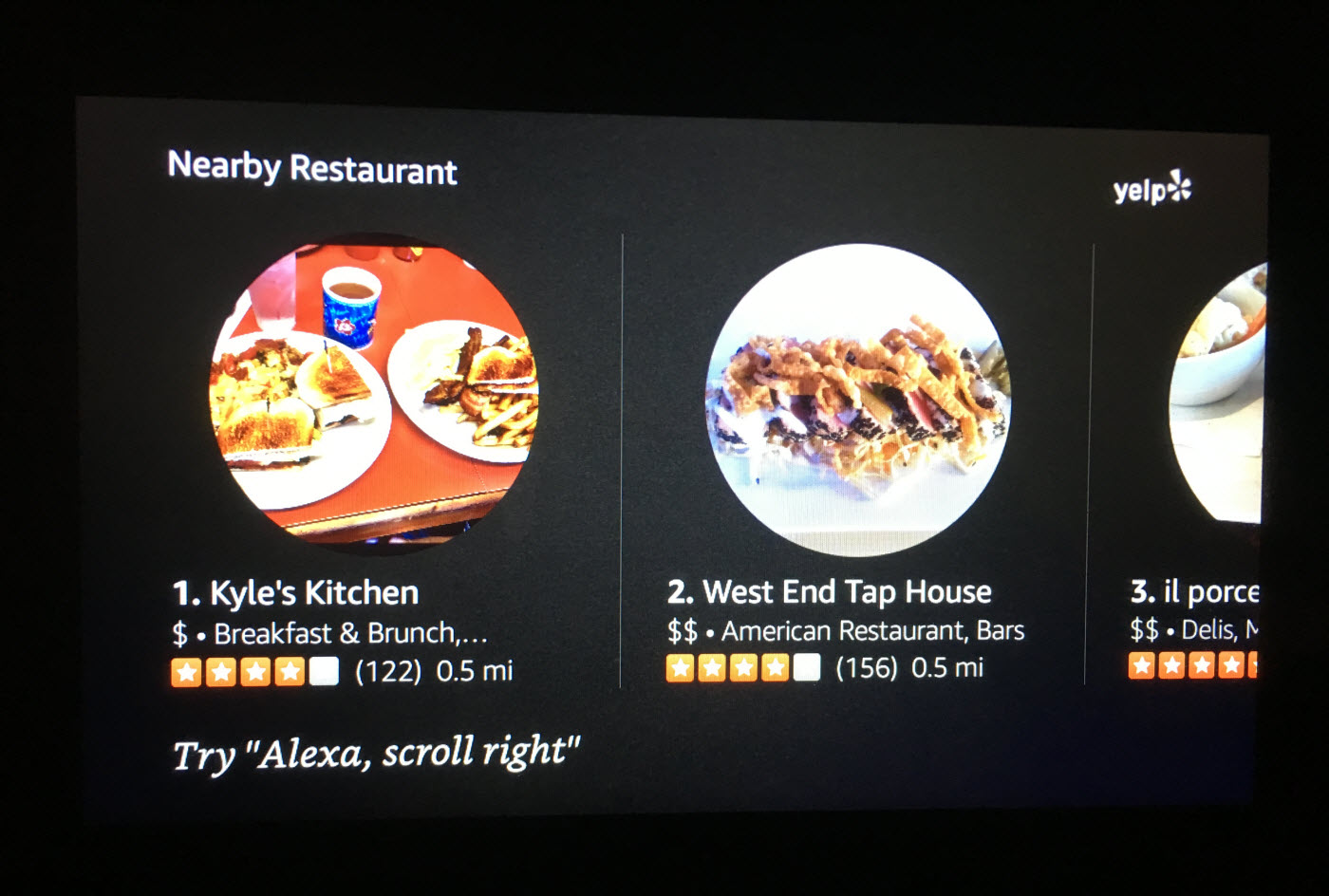
Когда возможно, Echo Show подталкивает пользователей к голосовому вводу информации, вместо прикосновения к экрану, предлагая вербальные команды, вроде «Попробуйте сказать: Алекса, пролистни вправо»
Интеграция голосового и экранного вывода информации с нуля
По сути, Voice-First представляет собой новый подход к проблеме интеграции голосовых команд в существующий графический интерфейс пользователя. Сначала GUI полностью исключается (как это осуществлялось в оригинальном Echo, который слушался только голоса), затем снова внедряется экран, и визуальная информация постепенно интегрируется как часть целостной системы.
Голосовое взаимодействие между людьми и персональными устройствами представляет собой новый и принципиально иной тип общения — и для пользователей, и для дизайнеров он аналогичен иностранному языку. Подобно тому, как иностранные языки легче всего освоить посредством погружения, изобретение и принятие голосового взаимодействия, вероятно, будут значительно улучшены средой, фокусирующейся исключительно на этом способе.
Некоторые интересные примеры инноваций, основанных на голосовом подходе, уже заметны в интерфейсе Echo Show:
- Последовательная нумерация результатов поиска, бывшая обычным явлением в раннюю эру веб-поиска, но с тех пор ушедшая в прошлое. На Voice-First-устройствах номера выполняют важную функцию: они предоставляют уникальные и эффективные словесные указатели, позволяющие пользователям эффективно выбирать элементы.
- Случайно отображаемые предлагаемые команды, такие как «Попробуйте сказать: Алекса, проиграй Эла Грина» или «Попробуйте сказать: Алекса, какое твое любимое слово?». Эта техника похожа на методы, используемые как Siri (Вещи, которые вы можете у меня спросить — Things you can ask me), так и Google Assistant (Исследовать — Explore), но отличается тем, что эти подсказки появляются не только в специально выделенной обучающей области, но также и в нижней части главного экрана, различных экранах с результатами поиска и на экране музыкального плеера. (Этот механизм обучения пользователя побуждает их к спонтанному взаимодействию с устройством. Но случайный контент означает также, что советы часто будут неинтересными и раздражающими для опытных пользователей, ведь эти подсказки нельзя отключить).
- Дисплеи с эффектом полного погружения, характеризующиеся богатым интерактивным контентом. Они являются привычными для традиционных веб- и мобильных GUI, но не для предыдущих голосовых интерфейсов Screen-First-устройств. Например, результаты рецептов в Echo Show включают детализированные экраны, показывающие ингредиенты, указания по приготовлению блюда и демонстрационное видео — и все это доступно с помощью голосовых команд.
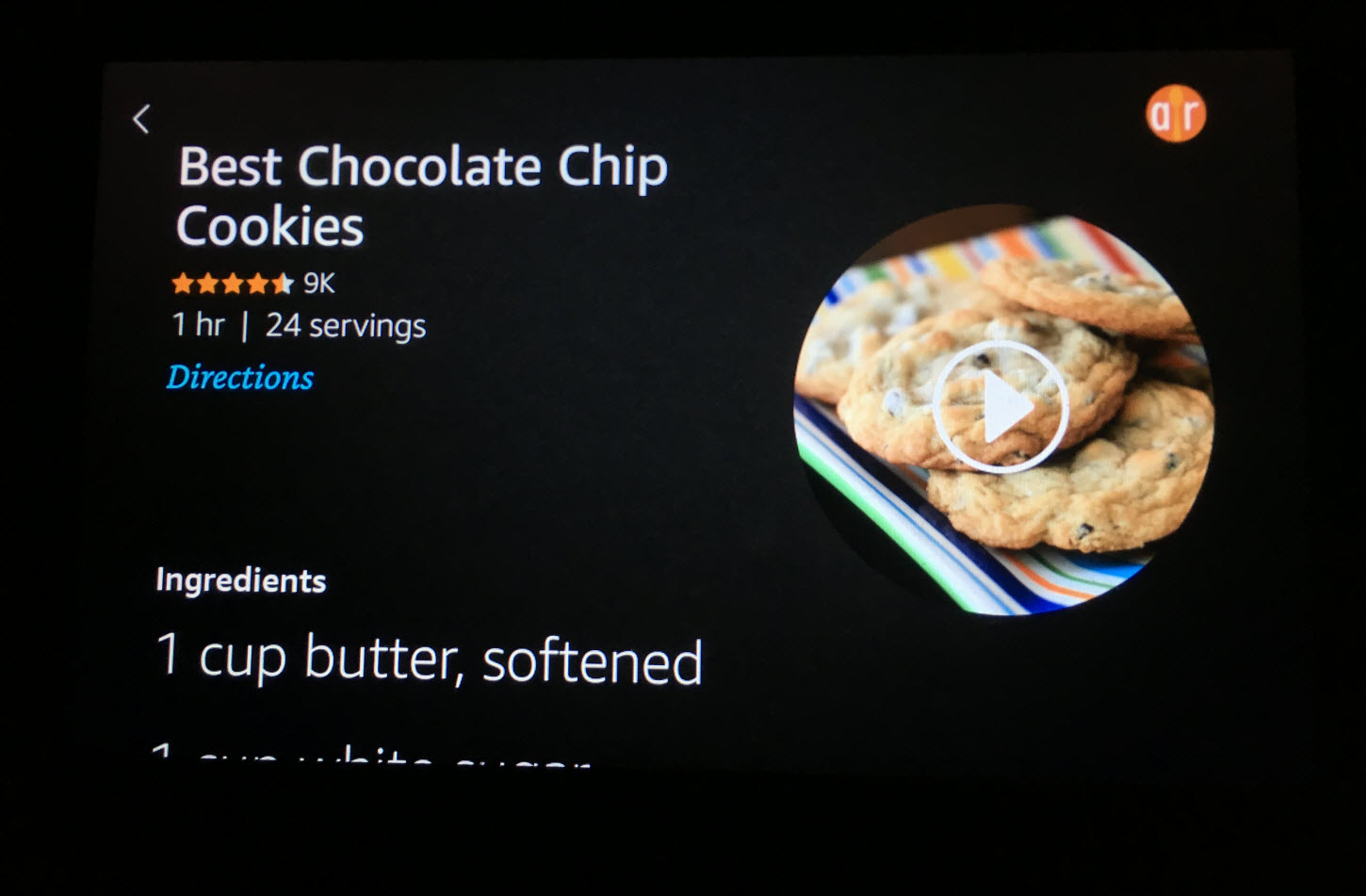
В качестве Voice-First-системы Echo Show не просто предоставляет ссылку на рецепт в GUI-приложении, но и включает управляемые голосом навигационные экраны, содержащие необходимые для приготовления блюда ингредиенты, указания и демонстрационным видео
Является ли Voice-First долгосрочным решением?
Удаление традиционных GUI-элементов, таких как меню и кнопки, может быть необходимым условием для понимания интерфейсов, базирующихся на голосовом взаимодействии. Но подобно движению Mobile-First (повлиявшего на появление неудачных идей, таких как скрывание основной навигации даже при работе на большом экране) концепция Voice-First не является панацеей. В конечном итоге, сознательное ограничение функциональности экрана во имя «чистого» голосового взаимодействия сокращает полезность дtвайса и увеличивает когнитивную нагрузку на пользователя и его разочарованность. Визуальный дисплей по своей сути является более эффективным способом (по сравнению с голосовым выводом) обеспечить доступ к большому объему информации.
Например, подход Voice-First означает, что, несмотря на свое название, Echo Show не будет на самом деле «показывать» вам ваш запрос, поскольку невозможно будет увидеть базовую информацию устройства, например, меню всех установленных приложений или, как их называет Amazon, «умений» (skills).
Алекса в настоящее время обладает библиотекой из 15 000 умений, доступ ко многим из которых осуществляется путем называния конкретного «скилла». Но даже если у пользователя будет установлена всего пара десятков скиллов, как, по мнению создателей, он должен их все запомнить? Персонализированные предложения и обработка данных на основе естественного языка может устранить необходимость обращаться к меню приложений, но до тех пор, пока речевые агенты не научаться читать наши мысли, они не смогут бесконечно предлагать все, что может заинтересовать пользователя в любой отдельно взятый момент времени.
Дизайн согласно принципу Voice-First может значительно улучшить голосовое взаимодействие, но в долгосрочной перспективе произвольное запрещение визуальных меню во имя взаимодействия только с помощью голоса будет похоже на попытку драться одной рукой, привязав вторую за спину. Имея в виду перспективу появления все более усложняющихся систем, требующих при этом целостности, а также «умных» голосовых и экранных интерфейсов, UX-дизайнерам стоит прибегать ко всем инструментам, к каким они только могут получить доступ.
Высоких вам конверсий!
По материалам: nngroup.com Источник картинки: kieransheik













