



Если вы читаете эти строки, то перед вами, скорее всего, стоит довольно непростая задача — оптимизировать конверсию сайта и одновременно поднять его рейтинг в поисковых системах. Может быть, вы даже пришли к выводу, что создать ресурс, соответствующий ожиданиям пользователей, при этом не нарушая требования современных поисковиков, — невыполнимая задача.
Но не стоит впадать в уныние. Цель данной статьи — рассказать вам о некоторых особенностях проведения сплит-тестирования, незнание которых может негативно повлиять на итоговое положение вашего ресурса в поисковой выдаче. Учитывая в своей работе данные рекомендации, вы сможете избежать любых непредвиденных проблем с поисковиками.
Удаление изображений после тестирования
Предположим, вы добились небывалых успехов в продажах новейшей модели смартфона от известного бренда. И вот вы решили провести сплит-тест посадочной страницы и выяснили, что вариант, демонстрирующий стандартное фронтальное изображение устройства, проигрывает тому, где смартфон показан в процессе использования.
Скорее всего, вашим следующим шагом будет удалить «неудачное» изображение. Однако, не стоит торопиться. Несмотря на то, что второй вариант показал более низкие результаты тестирования, полное удаление его с товарного лендинга может привести к тому, что пользователи, которые попали на ваш лендинг или сайт исключительно благодаря ссылке на изображение (или видео), вместо желаемой детальной картинки или ролика высокого качества получат ошибку 404. Неприятный сюрприз, не так ли? Google это точно не понравится.
Наилучшим решением здесь будет создать переадресацию удаленной страницы на действующую (301 redirect), или же пересохранить оба изображения под одним и тем же именем, избавив себя от подобных неприятностей и сохранив ваши позиции в рейтинге.
Скрытый контент
Некоторые программы для сплит-тестирования предлагают такую опцию обмана «поисковых пауков», когда за счет строки user-agent им выдается другая, более оптимизированная под запрос. Проблема данного метода заключается в том, что Google хочет видеть не «настроенный» специально под робота вариант, а такой же контент, что и пользователи. Несмотря на то, что данная практика имела широкое распространение около 10 лет тому назад, контент клоакинг (content cloaking) ушел в прошлое вместе с динозаврами. Сегодня он может повлечь за собой снижение рейтинга вашего ресурса, поэтому вам стоит отказаться от таких вариантов.
Что же делать тем, кто все-таки хочет скрыть тестовые страницы от бота Google?
Это довольно распространенная дилемма — оставить сайт видимым для поисковых систем, но предотвратить индексацию роботом «ненужного» контента. Некоторые разработчики используют специальный файл robots.txt, который содержит набор команд для «пауков», ограничивающий их доступ к конкретным файлам, страницам и каталогам.
Однако, несмотря на то, что Googlebot соблюдает данные инструкции, некоторые краулеры (crawlers) их обходят. Более того, даже если вы скроете некоторые страницы от индексирования роботом Google, они все еще будут доступны ему по ссылкам с других ресурсов. В таком случае, вы можете использовать альтернативный метод защиты содержимого, установив пароль на странице.
Проверить, была ли проиндексирована ваша тестовая страница, вы можете, забив в строку поиска
site: example.com/testpagename/,
где «example.com» ваш домен, а «testpagename» — имя страницы. Если Google показал ее в результатах поиска, это значит, что она была проиндексирована.
Чтобы этого избежать, вы можете добавить в <head> строку <meta name=”robots” content=”noindex”> или в файл robots.txt:
User-Agent: Googlebot
Disallow: /testpagename/index.html
(указав, соответственно, имя и расположение вашей тестовой страницы).
Если вы пользуетесь инструментами для веб-разработчиков (Webmaster Tools), с их помощью вы также можете настроить индексацию страниц.
Дублированный контент
Другой возможной причиной снижения позиции вашего ресурса в поисковиках является жесткая система наказания за дублированный контент. С точки зрения Google, нет никакого смысла в публикации двух одинаковых страниц, различающихся только изображением или заголовком.
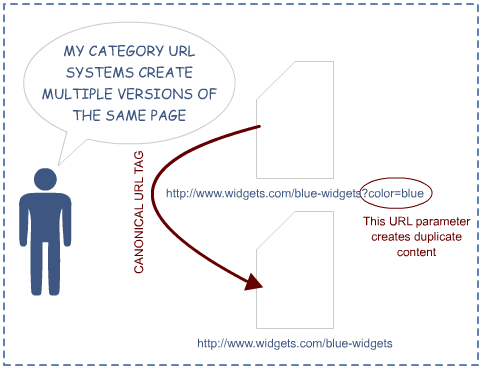
Хорошая новость состоит в том, что вы можете сообщить поисковому роботу, какую версию вашей страницы ему необходимо индексировать, благодаря тегу «rel=canonical».
<link rel=”canonical” href=”//www.example.com/mycontrolpage” />
(замените указанный url на адрес вашего сайта и имя контрольной страницы)
Это намного эффективнее, чем стандартный редирект, который зачастую приводит к распространенной проблеме зацикливания механизма переадресации.
Итак, при проведении сплит-тестирования необходимо:
- Определить для себя, какая страница (контрольная или тестируемая) будет доступна для индексирования.
- Добавить тег «canonical» на страницу, которую вы хотели бы скрыть, используя ссылку на страницу, открытую для индексирования.
- Вы также можете добавить тег «noindex» внутри тега <head> вашей скрытой страницы по образцу выше.
Если не вдаваться в технические подробности, можно сказать, что эти теги указывают Google на предпочитаемую версию url-адреса вашей страницы, исключив все ее дубликаты из индексирования.
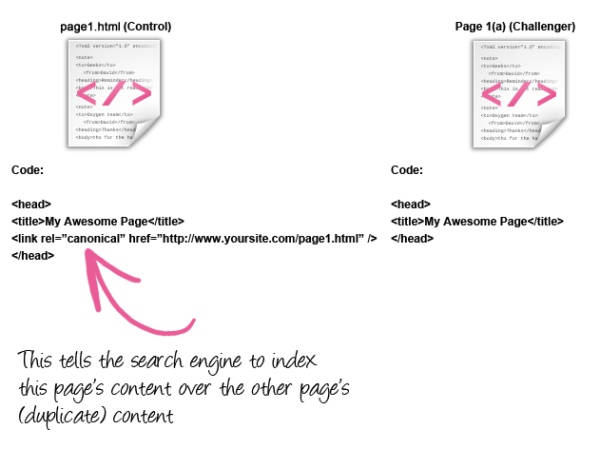
В данном примере для индексирования оставлен контрольный вариант
Вероятнее всего, вы тоже захотите оставить видимым контрольный лендинг, так как его url является основным для вашего сайта. Однако, каждый случай индивидуален, поэтому выбор за вами.
По окончании тестирования, вам необходимо:
- Обновить контент контрольной страницы, если тестируемая показала более высокие результаты (если нет, оставить все как есть).
- Удалить (или изменить) url «проигравшей» страницы
Стоит отметить, что существует много платформ, в том числе и LPgenerator, которые позволяют использовать один и тот же адрес url для всех страниц в процессе тестирования, что освобождает вас от необходимости использования тега «canonical» и всех остальных технических премудростей.
Высоких вам конверсий!
По материалам: blog.kissmetrics.com


















