


Практика показывает: проводя сплит-тесты, многие маркетологи даже не учитывают статистическую значимость. А это означает, что они принимают решения, руководствуясь неполными или даже неверными данными.
Тестирование для оптимизации конверсии не ограничивается простым разделением трафика между двумя версиями посадочной страницы: необходимо добиться результатов, отражающих поведение всей аудитории. Иными словами, результаты должны быть валидными.
Есть и хорошая новость: проводить правильные тесты может научиться каждый — это не квантовая физика. Достаточно знать основные принципы, чтобы избежать ошибок, из-за которых результаты тестов часто становятся сомнительными или вовсе бессмысленными.
Из этого поста вы узнаете:
- Почему валидные результаты так важны
- 3 главных угрозы при оптимизации
- Почему иногда нужно проводить исследования
- Как персонализация может усложнить ваши тесты
Тактика №1. Влияние (и цена) ненадежных данных
Маркетологи, не задумывающиеся о надежности своих тестов, не знают, что такая беспечность обходится им слишком дорого, в буквальном смысле. Результат тестирования во многом определяет стратегические решения, и недостоверность данных может направить вас по ложному пути, заставляя впустую тратить ценные ресурсы и время.
По оценке Флинта МакГлафлина (Flint McGlaughlin) из MarketingExperiments Web clinic, 75% или 80% всех тестов, проводимых компаниями, несовершенны из-за скрытых угроз валидности данных.
«Нет ничего хуже решений, принятых на основании недостоверных данных, — уверен МакГлафлин. — Не проводить никаких тестов может быть даже лучше, потому что тогда вы действуете осторожнее — без ложного чувства уверенности, которое внушают неверные данные».
Пол Чини (Paul Cheney), аналитик из MECLABS, высказывает похожую мысль: маркетологи, которые не проводят тестов, могут принимать даже более взвешенные решения, чем те, кто тестирует неправильно:
«Неправильно проведенные тесты дают вам обманчивое представление о происходящем, в итоге вы принимаете ключевые решения, основываясь на неверных данных. Такие решения — худшие на свете, потому что данные вроде как подтверждают, что вы правы, а на самом деле вы совершаете большую ошибку».
К сожалению, не менее 40% маркетологов, проводя тесты, не проверяют, надежны ли полученные данные. Они не просто тратят время понапрасну, а принимают неверные и, возможно, катастрофические для их компаний решения.
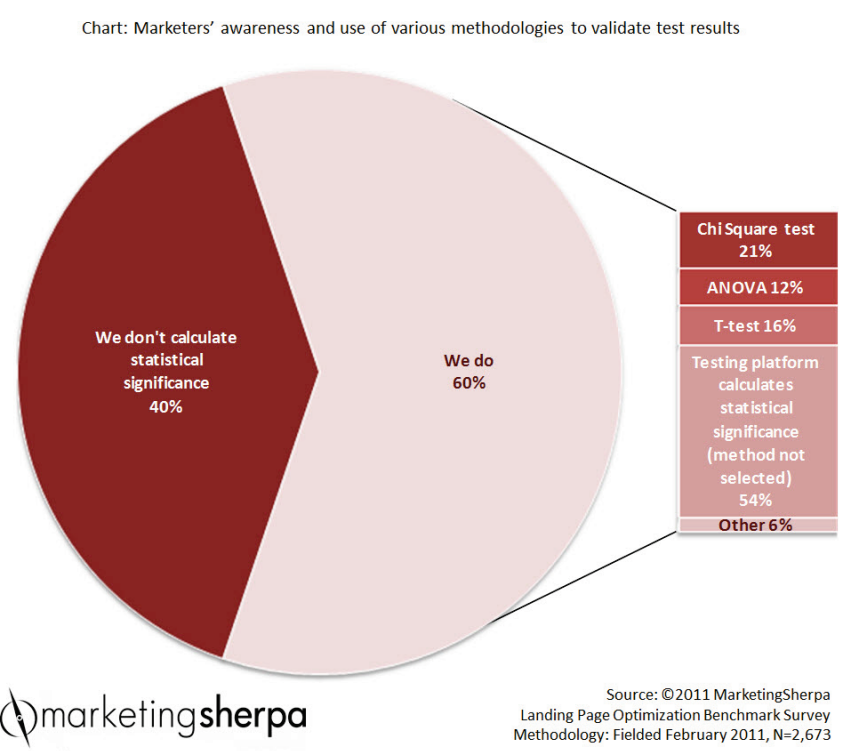
Диаграмма: знают ли маркетологи о разных методологиях проверки данных и пользуются ли ими
40% — мы не подсчитываем статистическую значимость
60% — используем:
ChiSquare test — 21%
ANOVA — 12%
T-Test — 16%
Методы подсчета статистической значимости, встроенные в платформу для тестирования, — 54%
Другое — 6%
Тактика №2. Контролируемая среда
Если вы не подготовитесь к тесту, он не сработает так, как вы хотели, или принесет вам ненадежные результаты. Поэтому прежде чем начать тестирование, спланируйте его, и ваши шансы получить валидные данные значительно вырастут.
В блоге Marketing Experiments Дэниел Берстейн (Daniel Burstein) описал некоторые ошибки, которые MECLABS совершили в ходе публичных сплит-тестов намеренно, в учебных целях.
Так, они провели тест для Copyblogger, чтобы выбрать лучшую тему среди предложенных читателями. Формат теста — публичный конкурс — предполагает угрозы валидности, которых обычно стараются избежать при нормальных обстоятельствах. В частности, тест проводился в неконтролируемой среде, где на его результат мог повлиять ряд переменных, таких как время голосования или количество доступных вариантов.
Берстейн комментирует: «A/B-тесты нужно проводить в контролируемой среде, чтобы эксперимент влиял только на переменные, связанные с KPI».
Иными словами, если вы проведете спонтанное тестирование, не создав контролируемой среды, вы никогда не узнаете, не сказались ли на результатах какие-нибудь случайные внешние факторы.
Цель любого теста — выделить тот единственный элемент, который вы тестируете, как можно сильнее, чтобы все прочие неуправляемые переменные не искажали результат. Для этого вам понадобится создать контролируемую среду, то есть устранить внешние факторы, насколько это возможно, и добиться, чтобы пользователи выбирали из двух тестовых вариантов в равных условиях.
Берстейн сказал, что главное достоинство сплит-теста — в том, что потенциальные клиенты не догадываются, что проходит тест. В данном примере это условие нарушено: конкурс был публичным, и участники, возможно, повели себя не так, как если бы не знали о проведении теста.
Тактика №3. Правильный размер выборки
Другой важнейший момент при разработке теста — выбрать размер сэмпла, достаточный, чтобы получить валидные результаты.
Берстейн пишет, что практически невозможно задать идеальный размер выборки, просто потому что вы не узнаете масштаба различий между результатами для тестируемых вариантов, пока тест не завершится. Если показатели обоих вариантов страницы не слишком отличаются, больший размер сэмпла помогает определить победителя, но если победитель совершенно очевиден, значит, вы могли получить полезные данные и с меньшей выборки.
Часто размер сэмпла определяет предположение о том, насколько большой должна быть аудитория, чтобы полученные от нее результаты были достойны доверия.
Обычно считается, что, чем больше сэмпл, тем лучше. Если он слишком мал, сложно сказать, применимы ли эти результаты к большим группам; к тому же, в такой ситуации мнения, личные предпочтения и вкусы даже нескольких участников могут сыграть заметную роль и сильно исказить результаты. Но маленьким компаниям или тем, у кого не так много клиентов, непросто собрать большую выборку.
Тактика №4. Обращайте внимание на внезапные перемены
В блоге MarketingExperiments Берстейн привел пример кейса, где ошибка при тестировании могла перечеркнуть все усилия команды.
Одна компания хотела выяснить, какой дизайн страницы лучше конвертирует, и запустила мультивариантный тест. Было создано три новых версии, помимо контрольной. Каково же было удивление команды, когда ни одна из новых версий не обошла контрольную на сколько-нибудь значительный процент.
Однако, анализируя данные, сотрудники компании обнаружили, что новые варианты обходили контрольный большую часть тестового периода — до тех пор, пока все не изменилось под конец. Примерно в это время был разослан емейл, направивший трафик на контрольную страницу, и результаты исказились. Исключив данные, полученные после отправки емейла, команда выявила однозначного победителя.
МакГлафлин описывает похожий пример. На конференции Optimization Summit HubSpot и MarketingExperiments создали лендинг для сбора емейлов в обмен на бесплатную главу отчёта MarketingSherpa об оптимизации посадочных страниц. HubSpot хотели собрать как можно больше емейлов и выяснить, какая страница лучше всего справится с этой задачей.
Компании создали три тестовые версии, и аудитория проголосовала за определенные переменные для тестирования, в том числе заголовок, главное изображение, разметку и призыв к действию.
В отличие от большинства тестов, этот длился всего 24 часа, но даже за это время компании успели увидеть очень интересные результаты. Сначала явным лидером была одна версия, а потом резко подскочила популярность другой.
Обычно такие ситуации — это тревожный сигнал, свидетельствующий об угрозе валидности. Оказалось, что посетители конференции делились в социальных сетях ссылками на одну из тестовых версий, привлекая на нее трафик и, следовательно, искажая результаты.
Тактика №5. Остерегайтесь эффекта контекста
Эффект контекста — это ситуация, в которой некое событие — важная новость, медийный тренд или нечто подобное — влияет на результаты теста и искажает данные.
МакГлафлин рассказывает о кейсе для онлайн-сервиса, предоставляющем базу данных лиц, совершивших преступление сексуального характера, для родителей, которых беспокоила безопасность детей в их районе. Владельцы сайта хотели повысить CTR своей PPC-рекламы и решили протестировать заголовок.
Команда создала четыре баннера и провела семидневный тест на 55 000 посещений. Три из четырех тестовых вариантов содержали слово «Хищник». По случайному совпадению во время тестового периода в документальном сериале «NBC: Дата» вышел специальный эпизод под названием «Поймать хищника», который привлек много внимания. Неудивительно, что заголовки со словом «хищник» оказались популярнее остальных.
В конкурсе, упомянутом в описании Тактики №2, тест проводился за неделю до Рождества. Два самых популярных варианта подчеркивали срочность, и наверняка здесь сказалось время проведения теста: перед праздниками многие люди торопятся завершить начатые дела, купить подарки близким и так далее.
Помните, что внешние факторы — то, что происходит в СМИ, или на YouTube, или еще где-нибудь в Интернете, — могут повлиять на результаты теста.
Вот несколько рекомендаций для того, чтобы избежать эффекта истории (или хотя бы заметить его):
- Отслеживайте данные каждый день, чтобы заметить любые внезапные подозрительные изменения.
- Тестируя заголовки и тексты, следите за их ключевыми словами с помощью сервисов оповещений вроде Google Alerts. Так вы узнаете, какие события могут повлиять на результаты теста.
- Проинформируйте сотрудников своей компании о проведении теста, чтобы они могли сообщить вам о потенциально релевантных событиях.
Тактика №6. Избегайте эффекта инструментария
Этот эффект возникает, когда источником ошибочных данных становятся сами инструменты для тестирования. Например, по какой-то причине ваш тестовый вариант загружается заметно медленнее, чем контрольный, а значит, многие люди не станут его даже читать, не то что кликать по кнопке CTA, которую вы тестируете. Вы можете даже не знать обо всех этих посетителях, покидающих страницу еще до того, как она полностью загрузится.
Загрузка и тестового, и контрольного вариантов должна быть одинаково быстрой, а пользовательский опыт — одинаково простым. Если одна страница заметно сложнее другой, это скажется на результатах теста. Долгая загрузка, длинный URL, проблемы с сервером или перенаправлением — это лишь некоторые причины эффекта инструментария.
С другой стороны, на достоверности результатов сказываются любые изменения в том, какие метрики используются и как они оцениваются — например, если вы используете разные инструменты аналитики для разных страниц. Если во время тестового периода с вашими инструментами аналитики возникают какие-то проблемы или что-то в них меняется, это тоже нужно учитывать.
Один из хороших способов решить эту проблему — использовать дополнительный инструмент аналитики и сравнивать его данные с данными основного. Тогда вам нужно использовать все инструменты на всех версиях страницы и сравнивать эквивалентные метрики. Как и в случае с эффектом контекста, следите за заметными отклонениями от нормы.
Тактика №7. Опасайтесь эффекта отбора
Эффект отбора — это заблуждение, что по какой-то части трафика можно судить обо всем трафике.
Один из примеров его проявления — тесты, в которых вы используете список своих лучших клиентов. Они наверняка более мотивированы, чем среднестатистические посетители сайта, и результаты теста будут соответствующими. Если по завершении такого теста вы сделаете победившую версию основной, вы можете увидеть совсем другие результаты у обычных посетителей, мотивация которых значительно ниже.
Ник Усборн (Nick Usborne), сотрудник MECLABS, говорит: «Если вы хотите опросить население Нью-Йорка о том, одобряют ли они налоговую реформу, и поговорите исключительно с посетителями ювелирного магазина Tiffany, из-за эффекта отбора вы получите недостоверные результаты».
Еще один пример связан с тестом, проведенным MarketingExperiments для крупного издательства. Маркетологи радикально изменили процесс подписки на сайте и протестировали новую версию, а в середине теста издательство запустило новую рекламную кампанию. За ночь средний уровень конверсии вырос с 0,26% до 2%. Если бы команда, проводившая тест, следила за переменами менее пристально, она могла бы подумать, что новая версия увеличила конверсию на 600%.
Также помните, что нельзя тестировать на аудитории, которая уже участвовала в предыдущем тесте. Для каждого следующего теста нужны новые пользователи.
Тактика №8. Проблемы последовательного тестирования
В последовательном тесте может быть гораздо больше угроз валидности, чем в простом сплит-тестировании: каждая стадия подвергается новым угрозам.
Диана Синдичич (Diana Sindicich), руководитель исследовательского отдела в MECLABS, сказала, что последовательные тесты особенно подвержены эффекту контекста:
«Например, емейл, отправленный по вашей подписной базе, привлечет больше трафика на любую доступную в этот момент версию домашней страницы, искажая результаты теста. В таких случаях вы обычно видите внезапный подъем на графике конверсии или трафика. Хотя это и не оптимальный подход к исследованию, так можно сравнить контрольную и тестовую версию. Полагаться на результаты следует лишь в том случае, если влияние эффекта контекста учтено и признано незначительным».
Если вы все же проводите последовательные тесты, вам стоит попытаться исключить или хотя бы ослабить все возможные угрозы валидности.
Тактика №9. Проблемы персонализации
Лаура Харкнесс (Laura Harkness), научный аналитик MECLABS, пишет, что персонализация контента — это, возможно, один из самых быстро развивающихся инструментов оптимизации, который позволяет маркетологам сегментировать посетителей и отправлять более персонализированные сообщения для оптимизации конверсии.
Хотя в целом она полезна, персонализация существенно осложняет проведение тестов. Во многих случаях один и тот же пользователь соответствует нескольким buyer persona, и некоторые сегменты накладываются друг на друга. Чтобы этого избежать, характеристики в отдельных образах должны быть взаимоисключающими, чтобы каждый пользователь попадал только в одну категорию. Конечно, есть у этого подхода и отрицательная сторона: каждый конкретный образ получит меньше трафика.
Высоких вам конверсий!
По материалам: marketingsherpa.com.


















