



Термин «карточная сортировка» (Card Sorting) относится к широкому спектру действий, связанных с группировкой и/или наименованием объектов или концепций. Объекты и концепции могут быть представлены в виде реально существующих карточек; в качестве виртуальных карточек, отображенных на мониторе; фотографий, существующих в физической или цифровой форме. Иногда сортировке подвергаются реально существующие объекты. Результаты могут быть выражены несколькими способами, причем основное внимание уделяется тому, какие элементы участники чаще всего группируют воедино, а также какие названия они присваивают категориям, полученным в результате сортировки.
Проводимый для целей проектирования взаимодействия/разработки UX процесс сортировки — обычно выполняемый потенциальными пользователями интерактивного решения, — обеспечивает:
- Релевантную терминологию (как люди на самом деле называют объекты/понятия)
- Отношения (близость, сходство)
- Категории (группы и их названия)
Полученную информацию можно использовать для того, чтобы решить, какие элементы должны быть объединены в группы (например, на электронных дисплеях); каким образом должно быть структурировано и маркировано содержимое меню; и, возможно, самое существенное — какие слова использовать для описания объектов, предназначенных привлекать внимание пользователей.
1. Практический пример
Представьте, что вы отвечаете за информационную архитектуру компьютеризированных весов с сенсорным экраном, все чаще встречающихся в больших супермаркетах (см. рисунок 1). Дисплей позволяет отображать одновременно 12 изображений и подписей. Поступали жалобы, что клиенты тратят много времени на взвешивание покупок и разочарованы тем, как организованы товарные категории. В таблице 1 показан список товаров, которые должны рассортировать участники эксперимента. Названия продуктов напечатаны на карточках со штрих-кодами, что позволяет упростить сбор данных (см. рисунок 2). На рисунке 3 показан пример таких карточек, уже организованных в группы. Поскольку это «открытый» вид опроса, то пользователи составляют свои собственные группы и имена для них. Эта конкретная группировка представляет собой текущее решение, называемое «ссылочной сортировкой» и реализованное в компьютеризованных весах, что будет рассмотрено дальнейшем.


Рисунок 1 A-Б: компьютеризированные весы с сенсорным экраном, показывающие категории фруктов и овощей, доступных в супермаркете.
Брокколи (Broccoli) | Лимоны (Lemons) |
Морковь (Carrots) | Личи (Lychees) |
Перец чили (Chillies) | Грибы (Mushrooms) |
Кабачки (Courgettes/Zucchini) | Лук (Onions) |
Фенхель (Fennel) | Апельсины (Oranges) |
Чеснок (Garlic) | Пастернак (Parsnips) |
Имбирь (Ginger) | Картофель (Potatoes) |
Грейпфруты (Grapefruit) | Тыква (Pumpkin) |
Виноград (Grapes) | Баклажаны (Squash/Marrows) |
Киви (Kiwi Fruit) | Брюква (Swede/Rutabaga) |
Лук-порей (Leeks) | Репа (Turnips) |
Таблица 1: Список товаров, которые можно найти на дисплеях весов в супермаркетах (см. рис. 1).

Рисунок 2: образец карточки со штрих-кодами для упрощения сбора данных (штрих-код обеспечивает возможность машинного «чтения» номера товарной позиции).

Рисунок 3: примеры карточек, организованных в группы.
Потратьте немного времени, чтобы подумать, как вы лично могли бы рассортировать эти товары. Для большинства покупателей существуют как минимум две группы подобных продуктов — фрукты и овощи. Но в большом супермаркете две группы будут включать в себя очень длинные перечни товаров, практически бесполезные без дальнейшей разбивки по категориям. Кроме того, вам могут встретиться незнакомые термины. Подвид длинных зеленых кабачков, который в британских супермаркетах продается под французским названием «Courgette», в американских магазинах можно обнаружить под итальянским наименованием «Zucchini». Когда подобные этим простые языковые различия известны заранее, то перечисление альтернативных названий единицы товара на одной карточке, вероятно, является удовлетворительным решением. Однако в новых проблемных областях или в мультикультурных/многоязычных ситуациях, когда терминология является более серьезной проблемой, участникам тестирования лучше предоставить возможность проводить сортировку по фотографиям или даже непосредственно при помощи объектов (с прикрепленной меткой штрих-кода).
Независимо от того что вы сортируете, результат будет одинаков: у вас будут некоторые объекты, организованные в группы — в идеале с названиями категорий. Следующая задача состоит в том, чтобы осмыслить принципы сортировки, особенно когда вы работаете с десятками или сотнями участников. Независимо от того, как проводится анализ результатов, есть, по крайней мере, два вопроса, ответы на которые нам необходимо знать:
- Какие названия получили группы (категории) и что именно вошло в каждую?
- Какие объекты чаще всего группировались вместе?
Будьте осторожны — это два отдельных набора данных. На то, что в выборочном исследовании грейпфруты и апельсины всегда были сгруппированы воедино, не повлияло использование нескольких различных названий категорий. Кроме того, неудивительно, что с грейпфрутами и апельсинами в одну группы группировались другие плоды, но характер этих дополнительных объектов варьировался с учетом подхода, принятого участниками. Если группу называли просто «фрукты», в нее включались яблоки, груши и другие плоды, а также грейпфруты и апельсины. Если же категория продуктов носила название «цитрусовые», то ее единственным возможным дополнением становились лимоны. Итак:
- Диаграмма сортировки объектов по группам показывает, как группы были названы участниками и что входило в каждую
- Диаграмма распределения объектов по каждому пункту демонстрирует, какие элементы чаще всего группировались воедино
1.1. Диаграмма сортировки объектов по группам
Вы можете создавать простые варианты диаграмм самостоятельно — пользуясь карандашом и бумагой или при помощи программы для работы с электронными таблицами и принтера. Для начала постройте диаграмму сортировки элементов по группам.
В крайнем левом столбце перечислите все объекты, подлежащие сортировке. Этот перечень необходимо составить для того, чтобы вы могли быстро найти каждый элемент списка, поэтому предпочтительнее использовать алфавитный порядок (применение текстового редактора или программы табличных вычислений может способствовать упрощению сортировки).
Просмотрев результаты сортировки, в заголовок столбца впишите название новой группы. Поставьте метку в ячейку каждого объекта, входящего в группу. Следовательно, если первая группа называется «Цитрусовые фрукты» (Citrus Fruit), мы напишем это наименование категории как заголовок столбца, а затем промаркируем ячейки для апельсинов (Oranges), лимонов (Lemons) и грейпфрутов (Grapefruit). Этот пример показан рисунке 4.
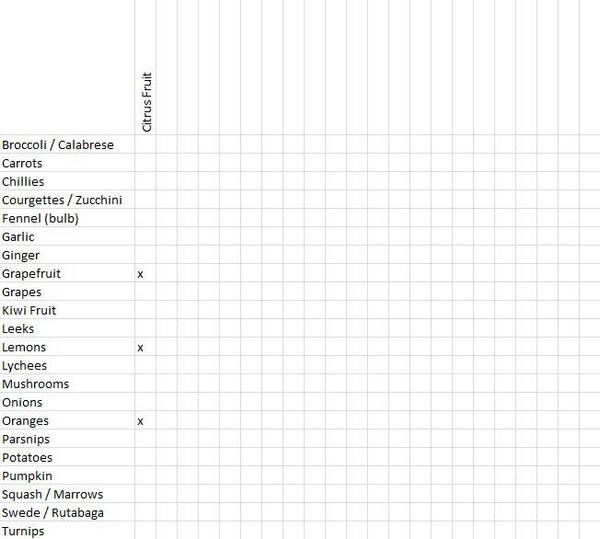
Рисунок 4: Таблица для сортировки по группам (для одной группы — «Цитрусовые фрукты»).
Если другой участник использует точно такое же название группы (или если сортировка проводится по типу «закрытого» опроса, где вы заранее предоставляете участникам все возможные наименования категорий), вам нужно будет расставить заголовки столбцов только один раз. Однако в случае «открытой» сортировки будьте готовы к тому, что вы получите множество формулировок групп. Например, «плоды» в противопоставлении с «ягодами». Как правило, во время сбора данных лучше всего разделять такие различные термины, чтобы решить на более позднем этапе, следует ли объединить подобные результаты сортировки.
Если бы мы переупорядочили объекты с использованием кластерного анализа (см. ниже), то получилась бы диаграмма, аналогичная диаграмме, показанной на рисунке 5. Она имеет тот же вид, что и рабочая таблица на рисунке 4 — перечень объектов с левой стороны, названия групп в верхней части. В теле диаграммы прямоугольные ячейки отображают количество раз, когда каждый элемент появлялся в названной группе, частотность появлений коррелирует с оттенком выбранного цвета, что соответствует количеству отметок, которые вы сделали бы в своей ручной версии. (На рисунке показан результат для элемента «Морковь» («Carrots») для группы «Корнеплоды» («Root Veg»).) В таблице 2 приведены более подробные сведения о используемом оттенке цвета как показателе частотности упоминаний.
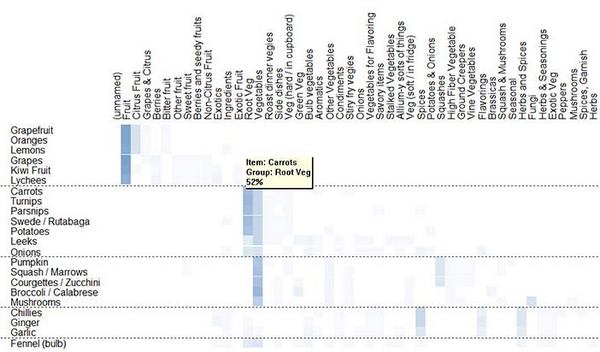
Рисунок 5: примерная таблица сортировки выборки фруктов и овощей по группам с 26 участниками (используется программа SynCaps V2).
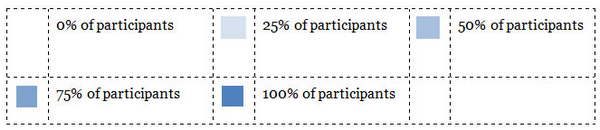
Таблица 2: примерная таблица сортировки выборки фруктов и овощей по группам с 26 участниками (используется программа SynCaps V2); % of participants — процент участников.
1.2. Диаграмма сортировки объектов по каждому пункту
Построение диаграмм сортировки объектов по каждому пункту требует приложения чуть большего количества усилий.
В левом столбце перечислите в алфавитном порядке все элементы, рассортированные участниками вашего эксперимента. Повторите список в том же порядке в верхней части страницы — теперь у вас есть матрица объектов. Чтобы избежать путаницы и дублирования усилий, нарисуйте линию по диагонали — и определите, какую половину матрицы вы будете использовать. Затем «затемните» вторую половину (см. рисунок 6). Это нужно для того, чтобы вы не могли разместить одну комбинацию в двух местах — например, «Апельсины и грейпфруты» и «Грейпфруты и апельсины».
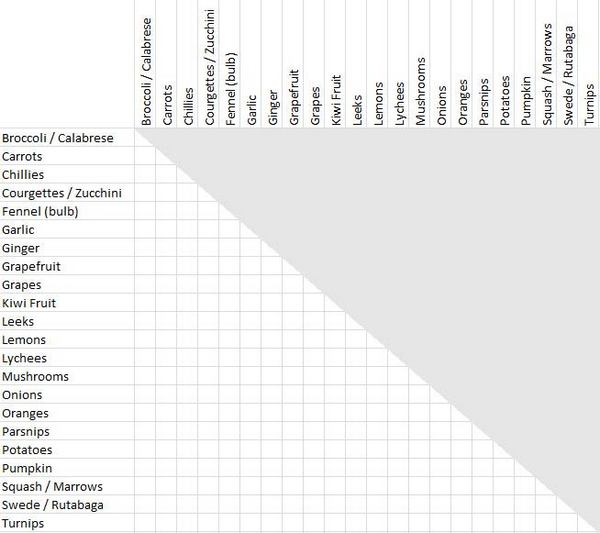
Рисунок 6: рабочая таблица для сортировки объектов по каждому пункту (создана в MS Excel).
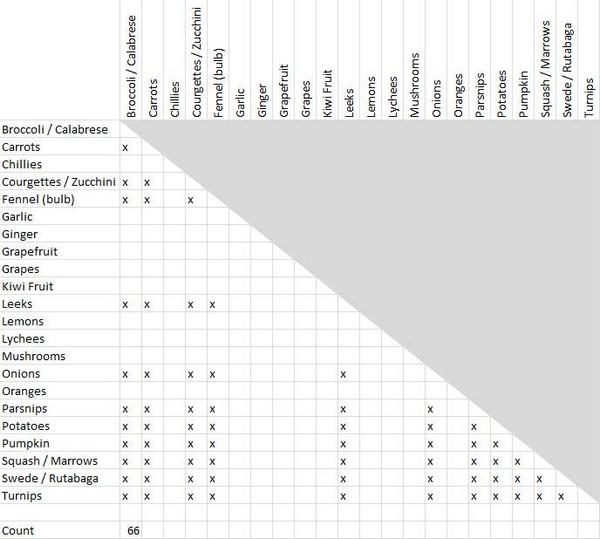
Рисунок 7: полученные пары элементов для группы из 12 объектов («Овощи»)
Используя отсортированные карточки, поставьте метку в каждой ячейке для всякой пары элементов, которые фигурируют в одной группе. Например, если мы обнаружим группу под названием «цитрусовые», мы, вероятно, найдем в ней грейпфруты, апельсины и лимоны, поэтому мы отметим ячейки для комбинаций «грейпфруты и апельсины», «грейпфруты и лимоны» и «апельсины и лимоны».
Это простой случай. Для больших групп существует множество пар, точное количество которых вычисляется по формуле:
(n^2 - n) / 2
Нужно добиться того, чтобы множество всех возможных пар (n^2) исключало сочетание элемента с самим собой (-n), к тому же нам не нужно различать порядок пар — так что комбинация «яблоки и груши» аналогична паре «груши и яблоки». Такой подход позволяет вдвое уменьшить матрицу и, следовательно, количество меток, которые должны быть проставлены, что в формуле выражается как (/ 2). Поэтому, если у вас есть группа из 8 объектов, приготовьтесь сделать отметки в 28 ячейках:
(8^2 - 8) / 2 = 28.
12 элементов дадут 66 меток, как показано на рисунке 7. (Имейте в виду, что это значения для одного участника. Либо сохраняйте общее количество в каждой ячейке, либо добавляйте дополнительные метки при обработке последующих участников. В качестве альтернативы используйте отдельный лист для каждого участника и просто суммируйте результаты по окончании опроса. Второй подход имеет явное преимущество, поскольку позволяет вам находить и исправлять ошибки, а также делать визуальные сравнения методов сортировки участников.)
Повторите опрос для всех участников. По завершении количество меток в каждой ячейке покажет вам, как часто участники группируют пары элементов вместе. На рисунке 8 показана версия, сгенерированная компьютером, причем элементы упорядочиваются с применением методов кластерного анализа. Вместо того, чтобы помечать строки и столбцы отдельно, имена элементов отображаются по диагонали. Обратите внимание, что, поскольку мы удалили половину матрицы, то большинство объектов «складываются» по диагонали. Например, «Морковь» (Carrots) начинается как строка слева, а затем продолжается как столбец, идущий вниз от диагонали страницы. Пунктирные линии на рисунке разделяют кластеры, сформированные на основе среднего количества групп, созданных участниками (общим числом 4).
Как вы помните, в диаграмме сортировки объектов по группам (рисунок 5) прямоугольные ячейки отображали процентное соотношение участников через оттенок выбранного цвета (таблица 2). Однако в диаграмме сортировки объектов по каждому пункту ячейки отображают, какие пары элементов были совместно причислены к одной и той же группе чаще всего.
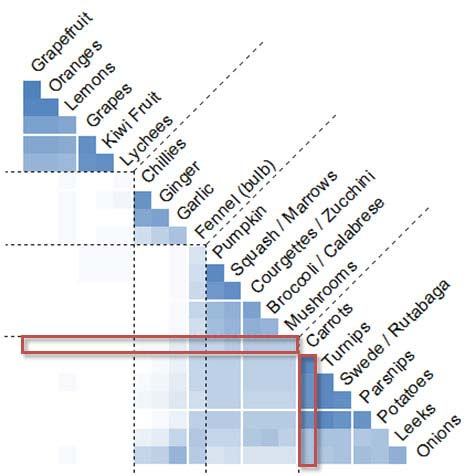
Рисунок 8: диаграмма сортировки объектов по каждому пункту для выборки фруктов и овощей, произведенная при помощи выборки из 26 участников (красной рамкой выделены полные данные для элемента «Морковь»).
2. Что означают результаты анализов
Хотя возникает соблазн предположить, что проект карточной сортировки немедленно обеспечит вас идеальной системой иерархической навигации, на деле это происходит редко. Результаты сортировки лишь предоставляют информацию, а не готовое решение. Пример рассматриваемого здесь «плодоовощного проекта» показывает реалистичный случай — полученные результаты далеко не окончательные.
Что мы можем наверняка узнать из анализа сортировки? Вернемся к рисункам 5 и 8 и, прежде чем продолжить, посмотрим, какие выводы можно сделать.
Обе диаграммы включают результаты кластерного анализа, которые делят элементы на четыре группы. Диаграмма сортировки объектов по группам (рисунок 5) показывает, что наиболее популярными названиями для этих четырех групп были «Фрукты» (Fruit), «Специи» (Spices), «Овощи» (Vegetables) и «Корнеплоды» (Root Veg). Название «Цитрусовые [фрукты]» (Citrus Fruit) было сильным претендентом на название группы, объединяющей грейпфруты, апельсины и лимоны, в то время как некоторые участники (около трети) не различали «Корнеплоды» и «Овощи».
А как насчет фенхеля (Fennel)? В обеих диаграммах можно увидеть, что фенхель был сгруппирован с большим количеством других товаров. Хотя кластерный анализ поместил его в группу под названием «Специи», почти 20% участников сортировали его в категорию «Овощи». Возможно, здесь ничего нельзя сделать, кроме как предоставить покупателям доступ к фенхелю из обеих групп — это легко реализовать на компьютеризированных весах или на веб-сайте.
На мгновение сосредоточив внимание на диаграмме сортировки элементов по пунктам, можно увидеть важную особенность самих объектов — независимо от названия групп. Очень немногие участники попытались сгруппировать фрукты с любым из овощей. Это говорит о четком понимании различия между этими двумя категориями, которое разработчики, безусловно, должны использовать при создании информационной иерархии. И напротив, диаграммы демонстрируют заметную неопределенность, существующую у участников в отношении лука и лука-порея. Эти два товара часто группировались с корнеплодами, но диаграмма сортировки предметов по пунктам показывает их близость — особенно для лука — с группой, обычно называемой «специями».
Какие выводы можно извлечь из этого примера? Первый состоит в том, что даже если вы многое поняли о признании и понимании участниками терминологии, категорий и концепций, подобное исследование — слишком ограниченное для того, чтобы применить его результаты к большему информационному пространству. В частности, небольшое количество фруктов, представленных в этом примере, побудило участников разместить их в одной группе. На практике подобное решение может быть неудачным, хотя в таблицах были предложения по уточнению категорий — «Цитрусовые [фрукты]» и «Ягоды» на рис. 5. Одним из решений было бы предоставление участникам более широкого спектра фруктов, в том числе так называемых образцов (репрезентативных типов) категорий, которые мы ожидаем увидеть в результатах опроса.
Альтернативным подходом было бы более детальное информирование и тщательный мониторинг участников. Это сложно сделать при сортировке онлайн — даже если инструкция очень подробная, участники могут не увидеть или не прочитать ее, либо не руководствоваться ею. Большинство из этих проблем можно преодолеть при очном участии в сортировке. Если координаторы видят, что участники формируют слишком мало категорий, они могут убедить их создавать больше подклассов сортировки.
К настоящему моменту мы затронули два самых популярных метода анализа результатов карточной сортировки — есть и другие, которые будут обсуждаться позже. Но сначала немного предыстории.
3. История карточной сортировки
Сортировка карт имеет удивительно долгую историю, особенно если учесть концепцию классификации по категориям. Именно древним грекам приписывают авторство понятия категорий, причем легендарный философ Аристотель создал основы для схемы классификации, которую мы в настоящее время используем в отношении растений и животных. Практика карточной сортировки в области социальных наук появилась гораздо позже, однако и она насчитывает более 100 лет существования.
Первоначально во множестве экспериментов в зарождающейся области экспериментальной психологии использовались отпечатанные типографским способом игральные карты, но сравнительно быстро они были дополнились пустыми карточками, позволяющими исследователям записывать слова, по которым классифицировались изучаемые объекты. Ранняя сортировка карточек в первую очередь касалась выяснения характеристик участников исследования — скорость сортировки применялась в качестве показателя умственной деятельности и времени реакции; функция запоминания и воображение изучались при помощи чернильных клякс, нанесенных на карточки. Некоторые из этих экспериментов превратились в то, что сейчас считается стандартным тестом на наличие неврологических проблем у пациентов, перенесших травму головы. Фактически, карточная сортировка была настолько хорошо воспринята в психологии, что еще в 1914 году в одном из самых авторитетных научных журналов мира «Science» («Наука») появилась статья, в которой признавались достоинства различных видов исследовательской деятельности с использованием карточек.
Сортировка карт также вошла в практику криминологии, исследований рынка, семантики и была принята в качестве стандартного инструмента качественных исследований в социальных науках. Однако в веб-проектировании данный метод появился только в начале 1990-х, где он использовался для выполнения задач по организации информационных пространств. Редчайшим исключением здесь является применение карточной сортировки для проектирования меню для операционной системы, осуществленное в начале 1980-х годов Томом Таллисом (Tom Tullis), одним из пионеров изучения HCI.
3.1. Карточная сортировка и проектирование интерактивных продуктов
Несмотря на популярность интернет-технологий карточная сортировка остается недостаточно широко используемым инструментом в практике разработки интерактивных продуктов. После опроса 217 участников Недели юзабилити 2008 года представители консалтинговой фирмы Nielsen Norman Group сообщили, что среднее число карточных сортировок, проводимых в течение года, составило 2. Хотя этот показатель вдвое выше, чем количество исследований с отслеживанием движений глаз (Eye Tracking), выявленное также в ходе этого опроса (в среднем 1 раз в год), он является удивительно низким, если учесть, что крупных инвестиций для проведения сортировки не требуется. По существу, карточная сортировка с момента своего создания играла лишь второстепенную роль в проектирования интерактивных продуктов, что, возможно, отражает ограниченное использование методов ориентированного на пользователя дизайна (User-Centered Design) в целом. Питер Морвиль (Peter Morville) и Луис Розенфельд (Louis Rosenfeld) в своей знаменитой книге «Информационная архитектура в Интернете» (Information Architecture for the World Wide Web) уделяют карточной сортировке всего несколько страниц, несмотря на то что в ее третье издание (2006 г.) они внесли множество корректив в соответствии с актуальными тенденциями в проектировании интерактивных веб-продуктов.
К настоящему времени существует только одна книга на тему применения карточной сортировки для интерактивных систем — это труд Донны Спенсер (Donna Spencer) «Карточная сортировка: проектирование используемых категорий» (Card Sorting: Designing Usable Categories), который — с точки зрения анализа —выглядит достаточно консервативным.
4. Преимущества карточной сортировки
Для проектирования взаимодействий, изучения удовлетворенности клиентов или изысканий в области социальных наук существует совсем немного исследовательских методов столь же эффективных, как карточная сортировка при работе с большим количеством концепций. В условиях очной сортировки обработка и аннотирование физических карт является довольно естественным и не подверженным посторонним воздействиям процессом: наблюдение за пользователями, участвующими в подобной деятельности, может дать исследователям глубокое понимание предмета и предоставить им богатый источник вопросов касательно изучаемой области.
Аналогичные результаты и возможности трудно получить при помощи интервью, анкет и оценок юзабилити, хотя каждая из этих альтернатив имеет свои преимущества в случае ее применения в более ограниченных областях исследования. Например, в ходе исследования юзабилити сайта можно относительно легко обнаружить, что один элемент меню называется нерелевантно с точки зрения пользователей, но подобный подход окажется непомерно дорогостоящим в случае необходимости протестировать нескольких десятков подобных объектов.
5. Качественные результаты в противопоставлении с количественными
С одной стороны, карточная сортировка может использоваться в индивидуальном режиме как инструмент для накопления информации и инициирования содержательной дискуссии между участниками мероприятия и исследователями. Результаты при таком подходе, как правило, обеспечивают лучшее понимание проблемной области с точки зрения пользователя.
С другой стороны, очень легко организовать онлайн-сортировку с участием сотен участников, чтобы узнать, вполне ли понятна представленная терминология и концепции широкому кругу пользователей. В то время как результаты индивидуального подхода в основном относятся к категории качественных, результаты крупномасштабных онлайн-исследований по преимуществу являются количественными. (Обратите внимание, что получить качественную информацию из онлайн-исследований невозможно, поскольку существует не столь много возможностей убедить участников онлайн-сортировок предоставлять полезную информацию посредством обратной связи.)
6. Что нужно сортировать?
Неудивительно, что выбор объектов/концепций, которые будут сортировать участники, во многом зависит от того, что пытается обнаружить исследователь, разработчик информационной архитектуры или дизайнер взаимодействия. Для проектов, начинающихся с нулевого цикла — то есть не имеющих каких-либо ограничений, налагаемых предшествующей работой — первоочередной задачей было бы создание словаря. В этом контексте пользователям могут быть продемонстрированы объекты, изображения или описания предметов, после чего участников попросят назвать показанное. Получившие название элементы могут быть сгруппированы, а группы, в свою очередь, поименованы. Это довольно легко сделать условиях очной сортировки, когда к объектам или фотографиям можно применить нумерованные или штриховые метки. (Обратите внимание, что некоторые веб-пакеты сортировки— такие как websort.net — позволяют сортировать фотографии, но не предоставляют пользователям возможности присваивать названия отображаемым элементам.)
- Определите и зафиксируйте объекты сортировки: если терминология уже установлена и неизменна (например, названия продуктов), то базовые исследования, которые описаны выше, проводить не нужно. Основная задача сортировки — выяснить, какие элементы следует группировать и как назвать сложившиеся группы (категории). Это относительно простое мероприятие как в случае индивидуального подхода, так и в режиме онлайн-опроса. Выбор метода в значительной степени будет определяться тем, нужна ли качественная обратная связь (для которой наиболее подходящей была бы очная сортировка с использованием бумажных карточек), или же более эффективным является получение качественной обратной связи от большого числа участников. В контексте очной сортировки релевантные качественные результаты могут быть получены от 15-30 участников, в то время как онлайн-сортировка может проводиться с привлечением сотен участников без каких-либо дополнительных затрат за исключением оплаты их труда. Кроме того, широкомасштабные исследования могут быть полезны для улучшения взаимодействия внутри организации или чтобы получить гарантию, что различные по составу группы пользователей обладают аналогичным пониманием проблемной области.
- Цели пользователей: карточная сортировка часто применяется для проектирования навигации по сайту. Однако простое перечисление названий документов, страниц или функций, которые будут представлены в проектном решении, не гарантирует, что пользователи смогут достичь своих целей, даже если навигация структурирована оптимальным образом. Следует начинать с целей — это помогает обеспечить эффективное проектирование навигации. Поэтому вместо того чтобы просить участников сортировать такие названия пунктов меню, как «Инструкция для сотрудников», «Кадровая политика» и «Руководство по персоналу» (каждое из которых дублирует остальные, вызывая путаницу), предложите им рассмотреть конкретные цели, которые пользователи имеют в виду, получая доступ к этим документам: «Найти продолжительность отпуска», «Могу ли я работать дома?», «Какой длительности будет мой отпуск по уходу за новорожденным ребенком?» и так далее. (Том Таллис использовал цели пользователей, когда применял карточную сортировку при разработке меню операционной системы.) Записи в журналах серверов — особенно поисковые фразы — результаты аудитов контента и опросы пользователей могут быть использованы для составления списка целей, применяемого в процессе карточной сортировки, обеспечивающей группирование и наименование категорий.
- Многоуровневые иерархии: большинство инструментов сортировки и анализа не поддерживают тип многоуровневой иерархии, наблюдающейся во всех — кроме самых простых — интерактивных решениях. Даже компьютеризированные весы, которые мы брали ранее в качестве примера для объяснения карточной сортировки, не могут использовать многоуровневую иерархию. Например, категория верхнего уровня под названием «Фрукты» может вести к «Цитрусовым фруктам», «Яблокам и грушам», «Экзотическим фруктам» и так далее. Однако отсутствие поддержки анализа многоуровневой иерархии не является непреодолимой проблемой. На самом деле, многоуровневые иерархии на этапе анализа могут существенно увеличить сложность сортировочной деятельности, тем самым делая ее для многих участников сложной задачей. Вместо этого выполните несколько одноуровневых операций сортировки. Сосредоточьтесь на самых низких уровнях («листья» дерева навигации), поскольку названия категорий, предоставленные участниками, часто значительно различаются по уровню обобщения, как мы уже видели в примере. Названия категорий, придуманных участниками, включали в себя «Фрукты», «Плоды» и «Ягоды». Каждое из этих названий может быть уместным для заголовков навигации более высокого уровня. (Многоуровневая сортировка рассматривается более подробно в разделе 9 «Расширенный анализ».)
7. Как осуществить карточную сортировку

7.1. Выбор одного из подходов
Методы очной сортировки, как правило, лучше приспособлен для качественных исследований, в то время как онлайн-методы (на базе веб-технологий) больше подходят для получения количественных результатов. Однако этой утверждение не всегда является правильным; например, можно сесть рядом с участником или поделиться доступом к своему компьютеру, пока проводится онлайн-сортировка. Такие действия могут привести к получению хороших качественных данных, однако подобная практика представляется как смущающая участников и усложняющая работу координаторов. Совместное использование удаленных рабочих столов также может быть технически сложным, особенно при наличии корпоративных брандмауэров и политик безопасности.
Исследователи или разработчики UX также могут выбирать между:
- открытой сортировкой, в которой пользователи формируют свои собственные категории;
- закрытой сортировкой, где категории заранее определены;
- гибридной сортировкой, представляющей собой некую комбинацию двух предыдущих.
Для большинства целей открытая сортировка — лучший выбор, хотя предоставление предварительно определенных категорий во всех случаях является полезным для участников и поддерживается большинством инструментов сортировки и анализа. Закрытая сортировка может использоваться при попытке установить изменения, необходимые для существующей структуры, особенно с инструментами анализа, которые обеспечивают сравнение между контрольным образцом (таким как существующее или предлагаемое решение) и результатами участников (см. рис. 9).
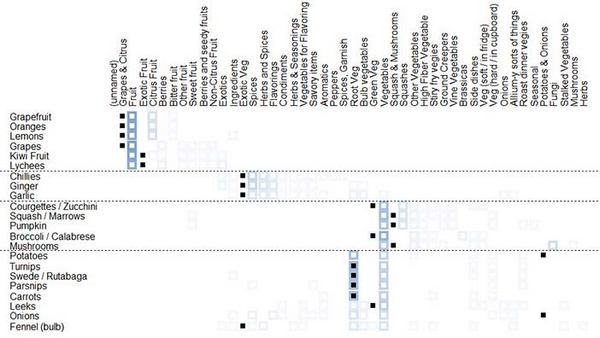
Рисунок 9: пример сортировки фруктов и овощей с использованием контрольного образца, показывающего уже существующее решение.
На этой диаграмме сортировки объектов по группам (рис. 9) текущее решение показано черными квадратами в ячейках. Так что, хотя большинство участников предпочитают группировать все фрукты вместе, компьютеризированные весы используют две необычные группы: «Виноград и цитрусовые» (Grapes & Citrus) и «Экзотические фрукты» (Exotic Fruit). Тем не менее существуют некоторые области совпадения: многие участники согласились с нынешней структурой группы «Корнеплоды» (Root Veg), расположенной чуть ниже центра диаграммы.
7.2. Рекрутинг и инструктирование участников
Как и в любом другом случае использования ориентированного на пользователя проектирования участники карточной сортировки должны быть представителями сообщества пользователей, на которых рассчитано конкретное программное решение Тем не менее, учитывая трудности, которые могут испытывать некоторые представители целевой аудитории в обращении с технологиями (например, пользователи старшей возрастной категории), часто бывает полезно перепроверить эти «группы риска» для того, чтобы гарантировать, что полученный результат будет приемлем для максимально широкой аудитории. Там, где это возможно, попробуйте вовлечь в сортировку участников, которые мотивированы еще чем-то кроме сугубо денежных интересов — существующих пользователей или клиентов, например.
При инструктировании участников сортировки не нужно формулировать требования слишком расплывчато. При разработке навигации по сайту количество категорий, необходимых для набора предметов, совершенно не скрывается от участников. Между количеством и размером групп, как правило, поддерживается приблизительное равновесие. С учетом всего этого важно предоставить участникам адекватную информацию о количестве и уровне требующихся вам групп. Если вы, например, пытаетесь разработать меню для компьютеризированных весов, на дисплее которых можно разместить только 12 наименований товаров, то не стесняйтесь сообщить участникам об этом. Аналогичным образом горизонтальные панели меню на веб-сайтах или в интерфейсах компьютерных программ редко имеют место для более чем 6 или 8 элементов. Предоставление участникам возможности генерировать 20 или 30 категорий в этих случаях является потенциальной потерей их и вашего времени.
Аналогичным образом, если у вас есть известные вам названия групп, или, по крайней мере, вы знаете, какие именно наименования категорий вам нужны, то предоставьте эту информацию участникам. Это можно сделать как при очном режиме, так и при онлайн-сортировке. Но поощряйте участников к тому, чтобы они придумывали свои собственные названия категорий, если они сочтут желательным.
Участники также должны быть проинформированы о том, как обращаться с непонятными им объектами. В то время как некоторые исследователи или разработчики полагают, что все до единого элементы должны быть отсортированы, предоставление участникам возможность просто угадывать категории неизвестных объектов может привести к сомнительному группированию.
Попросите пользователей просто не сортировать элементы, которые им неизвестны, или создать определенную «неизвестную» группу для их размещения. Их можно исключить из результатов. Большинство онлайн-инструментов сортировки в настоящее время позволяют элементам оставаться несортированными. Однако убедитесь, что результаты анализа основаны на количестве участников, а не на количестве раз, когда предмет был отсортирован.
7.3. Время сортировки
Количество времени, необходимое для выполнения сортировки, может совершенно различаться от одного участника к другому, но в значительной степени зависит от числа элементов, подлежащих сортировке:
Примерная длительность сортировки:
- 20 минут для 30 объектов
- 30 минут для 50 объектов
- 60 минут для 100 объектов
Однако существуют и другие факторы, к числу которых относится то, насколько участникам знакомы термины и концепции, и насколько они мотивированы добросовестно обеспечить получение релевантных результатов. Кроме того, в ходе отдельного сеанса можно сортировать до 150 карточек, однако более качественные результаты можно получить, разбив такой крупный проект на более мелкие части.
7.4. Подготовка сортировки
В ходе очной сортировки (с применением бумажных носителей) нанесение на карточки названий объектов и групп может стать трудоемким занятием. К счастью, для упрощения этой задачи названия элементов могут быть напечатаны либо на карточках, либо на самоклеящихся этикетках.
Бесплатные шаблоны для Microsoft Word можно найти на веб-сайте Syntagm. Шаблоны также содержат штрих-коды, которые можно использовать для упрощения сбора данных: вместо ручного ввода названия или номера объекта штрих-коды с помощью простого USB-сканера позволяют читать данные напрямую с карточек. Этот способ быстрее, и он меньше подвержен ошибкам, чем запись данных вручную — это позволяет относительно легко обрабатывать 120 и более карточек или в минуту (полные инструкции находятся на упомянутой веб-странице).
Подготовка к онлайн-сортировке относительно проста, поэтому необходимо только загрузить на сайт списки элементов и названия групп (если они есть).
Однако — независимо от метода сортировки — имейте в виду, что поверхностное сходство в используемых названиях может привести к получению бесполезных результатов. Рассмотрим эти наименования пунктов меню из интрасети предприятия:
- Управление пропусками рабочего времени и выходными/праздничными днями
- Управление отношениями с «трудными коллегами»
- Управление изменениями
При столкновении с необходимостью отсортировать большое количество предметов участники могут просто сгруппировать их воедино по схожести названий. Это называется поверхностным совпадением. Чтобы преодолеть его, рассмотрите возможность изменения названий подобным образом:
- Пропуски рабочего времени и выходные/праздничные дни
- Отношения с «трудными коллегами»
- Управление изменениями
В первых двух пунктах слово «управление» не являлось важной составляющей названия. Удаление подобного «балласта» или использование синонимов предотвращает нежелательную группировку.
7.5. Выбор названий объектов и групп
Наряду с вопросом поверхностного сходства, упомянутым выше, проявляйте осторожность при выборе общеупотребительных названий, особенно когда интерактивные решения разрабатываются для самого широкого круга пользователей, среди которых могут оказаться люди с ограниченными возможностями. Это не просто здравый смысл, но также требование законодательства о недопущении дискриминации в отношении инвалидов, действующее во многих странах. Проще говоря, язык должен быть не более сложным, чем необходимо для передачи необходимой информации.
Например, в английском языке более длинные слова (с большим количеством слогов) используются гораздо реже, чем короткие. И хотя участники карточной сортировки могут предлагать необычные названия для предметов или групп — такие, например, как ботанический термин «Brassica («капуста» на латыни), — большинство людей при покупке в местном супермаркете вряд ли будут использовать столь узкоспециализированное наименование этого овоща. Если у вас возникают сомнения относительно того, часто ли употребляется то или иное слово, то загляните для справки в частотный словарь соответствующего языка.
8. Как понять результаты сортировки
В случае очень маленького проекта полезную информацию о группировании объектов можно получить, просто пролистав отсортированные вручную карточки или просмотрев список результатов онлайн-сортировки. Однако для крупных проектов вам потребуется применить определенную форму аналитики — начиная от составления простой таблицы и заканчивая кластерным анализом. Обратите внимание на то, что хотя кластерный анализ потенциально является весьма сложным предметом, большинство инструментов карточной сортировки использует довольно простую форму этой статистической процедуры, позволяющую вручную осуществить кластеризацию объектов. Этот метод известен как иерархический кластерный анализ (Hierarchical Cluster Analysis, HCA). Термин «иерархия» в этом случае подразумевает то, как агрегированные мелкие кластеры образуют более крупные, пока все они не будут включены в единую структуру.
8.1. Простой анализ
Простая табличная сводка распределения элементов по группам может строиться вручную (как описано выше) или с использованием программы табличных вычислений. Однако онлайн-инструменты сортировки могут сделать этот анализ вместо вас. Для печатных карточек с использованием шаблонов для Microsoft Word, описанных ранее, программа SynCaps V2 и более ее поздние версии умеют проводить кластеризацию элементов по пунктам, элементов по группам и анализировать древовидные диаграммы (Dendrogram — дендрограммы).
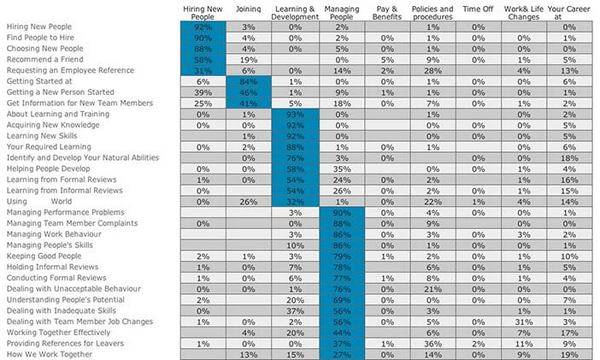
Рисунок 10: табличная сводка сортировки элементов по группам, предназначенная для разработки навигации по интрасети и созданная с использованием онлайн-программы, предназначенной для оптимального сортирования.
Рисунок 10 представляет собой диаграмму сортировки объектов по группам, показывающую представление данных, альтернативное тому, что и на рисунке 5. В обоих случаях список объектов расположен в левой части диаграммы, а названия групп — в верхней части. Был проведен кластерный анализ, чтобы определить, какие элементы наиболее тесно взаимосвязаны, создавая упорядочение элементов, перемещающееся из одного кластера в другой. Единственное существенное различие между этими двумя графическими представлениями результатов сортировки состоит в том, что на рисунке 5 для отображения относительной силы каждой взаимосвязи используется затенение, а на рисунке 10 наиболее значительные процентные показатели выделены синим цветом.
8.2. Кластерный анализ
Тип кластерного анализа, выполняемого большинством инструментов карточной сортировки — это иерархический кластерный анализ. Обычно его результатом является графическое отображение, называемое древовидной диаграммой, или иногда дендрограммой, термином, который буквально уходит корнями в греческое слово «дерево — dendron.
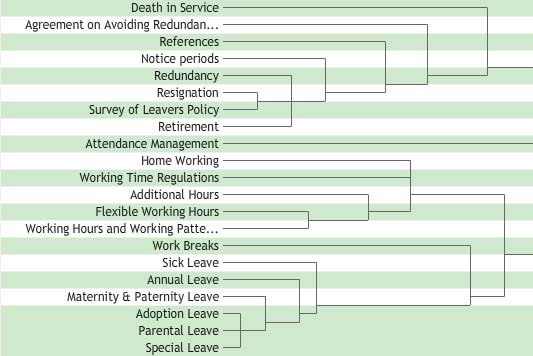
Рисунок 11: древовидная диаграмма навигации по интрасети, созданная с использованием облачного приложения Websort.
Рисунок 11 показывает иерархический кластерный анализ в виде дендрограммы. Этот пример взят из операции сортировки, применяемой при проектировании навигации по интрасети. Иерархический характер древовидной диаграммы связан с прочностью взаимоотношений между элементами, измеряемой тем, как часто они оказываются в одних и тех же группах. На дендрограмме — по аналогии с настоящими деревьями — действует положение: чем короче ветвь, тем она прочнее.
На рисунке 11 все шесть нижних элементов включают слово «Отпуск» (Leave). Тем не менее участники прежде всего помещали в одну группу «Отпуск в связи с усыновлением/удочерением» (Adoption Leave), «Отпуск по уходу за ребенком» (Parental Leave) и «Специальный отпуск» (Special Leave) как тесно взаимосвязанные, однако в меньшей степени согласующиеся с «Отпуском по беременности и родам и отпуск по уходу за ребенком для отцов» (Maternity & Paternity Leave), «Ежегодным отпуском» (Annual Leave) и «Отпуск по болезни» (Sick Leave). Наконец, «Перерывы» (Work Breaks) иногда объединялись в одну группу с элементами, касающимися отпуска, однако эта взаимосвязь является довольно слабой по сравнению с остальными. Если вы хотите знать, почему связь элемента «Перерывы» слабее прочих отношений, вам нужно будет обратиться к диаграмме сортировки объектов по пунктам, диаграмме сортировки объектов по группам или необработанной матрицей близости, если таковая имеется — последняя просто показывает количество раз, когда каждое сочетание элементов появлялось в одних и тех же группах.
Древовидная диаграмма также дает некоторое представление о том, как работает кластерный анализ. Используемый метод называется «агломеративная (объединительная) кластеризация», а это означает, что мы строим кластеры снизу вверх. Таким образом, в примере с интрасетью первый кластер должен начинаться с трех последних элементов, содержащих в названии слово «Отпуск» (Leave) — у них самые короткие ветви — и продолжаться «Отпуском по беременности и родам и отпуск по уходу за ребенком для отцов» (Maternity & Paternity Leave), впоследствии включенным в кластер. Затем, снова взглянув на рисунок 11, мы обнаружим, что следующие наиболее выраженные взаимосвязи присутствуют в верхней части диаграммы, например, между пунктами «Заявление об уходе» (Resignation) и «Опрос касательно политики отпусков» (Survey of leavers policy).
Поскольку элементы агломерируются (объединяются) в кластеры, то рассчитывается средний балл, основанный на количестве пар элементов, входящих в одни и те же группы. Древовидная диаграмма показывает, насколько далеко вертикальные соединительные линии отстоят от названий объектов. Как упоминалось выше, чем короче соединяющие «ветви», тем более тесные взаимоотношения они отображают, то есть когда вертикальные соединительные линии находятся ближе к наименованиям элементов — как в случае трех нижних элементов на рисунке 11.
На дендрограмме кластеры объединяются в ветви до тех пор, пока все объекты не будут включены в иерархическую структуру. Это означает, что самые слабые взаимоотношения — между разнородными кластерами — на диаграмме будут находиться дальше всего от названий элементов. Хотя на рисунке 11 древовидная диаграмма показана не полностью, она включает в себя три длинные ветви, которые продолжаются вправо, выходя за пределы изображения. Они представляют собой три разнородных кластера; для каждого из них потребуются собственные наименования категорий, которые могут быть получены из диаграммы сортировки элементов по группам. Обратите внимание, что дендрограммы не учитывают названия групп: вполне возможно, что несмотря на то, что «Отпуск в связи с усыновлением/удочерением» (Adoption Leave), «Отпуск по уходу за ребенком» (Parental Leave) и «Специальный отпуск» (Special Leave) часто группировались воедино, участники, возможно, применяли к этой группе широкий спектр разнообразных названий. Также имейте в виду, что на древовидной диаграмме элементы могут отображаться только в одном месте. Поэтому, если элемент распределяется участниками поровну между двумя разными группами, он будет представлен как слабая взаимосвязь только в одной из них. Вам нужно будет просмотреть таблицу распределения объектов по группам, чтобы заметить это.
9. Расширенный анализ
Пытаясь понять результаты карточной сортировки, исследователи неизменно сталкиваются с двумя часто возникающими проблемами. Во-первых, не все участники имеют одинаковую мотивацию, опыт или потребности. Это означает, что у нас могут быть участники, чьи результаты — просто «помехи», что особенно актуально для онлайн-сортировки с применением привлекательных стимулов. В других случаях мы можем полагать, что у нас есть одна относительно однородная группа участников, когда на самом деле мы располагаем разнообразной по составу и сегментам аудиторией. Это может быть обусловлено таким всеобщим фактором как опыт — в этом случае мы должны учитывать эти многочисленные группы в наших разработках.
Разнообразие также может быть связано с различными контекстами использования. В последнем случае мы должны попытаться понять различия и решить, оправданы ли отдельные разработки. К сожалению, традиционные инструменты анализа карточной сортировки здесь не очень помогают. Но часть этой информации может быть получена вручную — путем изучения количества и размера групп, созданных каждым участником: например, те, кто спешит, имеют меньше групп и большое количество предметов в бесполезных категориях, таких как «Не знаю» или «Разное», в то время как те, кто обладает существенно отличающимся представлением о проблемной области, могут создавать необычное — по сравнению со средним показателем — количество групп.
Вторая повторяющаяся проблема связана с основным принципом кластерного анализа: каждый элемент относится к одному конкретному кластеру. В определенной степени данное условие можно обойти, тщательно проверив анализ сортировки объектов по пунктам и объектов по группам. Например, такой объект как огурец можно распределить поровну между «Зелеными овощами» и «Овощами для салата». Он появится на древовидной диаграмме в любой из этих групп — ее выбор будет произвольным, если распределение в точности равно 50:50 — при достаточной слабой взаимосвязи с выбранной категорией. Однако слабость взаимоотношения вовсе не означает того, что участники были смущены тем, к какой группе они должны отнести элемент — они просто не согласились с предложенной категоризацией. Диаграммы сортировки объектов по пунктам и элементов по группам могут четко продемонстрировать это. Однако из-за этого ограничения кластерного анализа некоторые исследователи используют другие передовые статистические методы — прежде всего факторный анализ.
9.1. Многоуровневая сортировка
Основной метод сортировки, обсуждаемый в этой главе, может быть описан как одноуровневый или «плоский». Участникам предоставляется набор объектов, которые они должны сортировать на группы одного уровня. Несмотря на возможное искушение начать создавать вложенные группы — «листовые овощи» в «зеленых овощах» внутри «овощей», например — существуют две проблемы, о которых необходимо знать:
- Ограниченность аналитики: наиболее распространенные методы анализа используют единый показатель близости или смежности объектов, связанных между собой. Подобный подход основывается на том, насколько часто элементы помещаются участниками в единую группу. Нецелесообразно выполнять кластерный анализ на нескольких групповых уровнях, но относительно просто применять весовые коэффициенты к близости элементов в зависимости от того, появились ли они в одной группе, подгруппе, подгруппе подгруппы и т. д. Элементы, которые появляются вместе в одной и той же группе, получат наивысший весовой коэффициент, пары, распределенные между ближайшими подгруппами — несколько более низкий; те, которые разделены между подгруппами второго порядка — еще более низкий (и так далее). Например, огурец и цуккини получат максимальный весовой коэффициент, если оба овоща появятся в группе «Зеленые овощи», но им обоим будет присвоен более низкий коэффициент, если кабачки появятся в группе под названием «Зеленые овощи» (Green Vegetables), а огурцы — в подгруппе под названием «Овощи для салата» (Salad Vegetables). (Это показано на рисунке 12 с использованием максимального весового коэффициента, равного 2). Это подход, расширенный до нескольких уровней сортировки, применяется в таких облачных инструментах как UXsort (uxsort.com) и SynCaps V3 (Syntagm Ltd). SynCaps V3 также обеспечивает анализ имен подгрупп, используемых на каждом уровне.
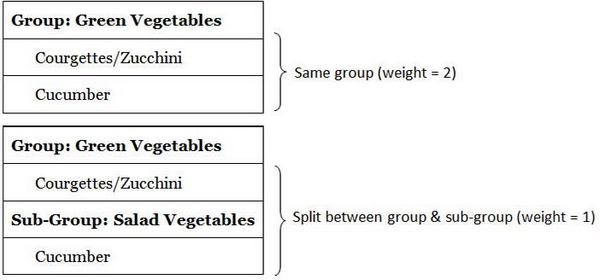
Рисунок 12: пример использования многоуровневого весового коэффициента.
- Масштаб и сложность: одной из самых больших проблем при многоуровневой карточной сортировке является значительное увеличение количества сортируемых объектов и получаемых решений. Следовательно, было бы нецелесообразно предоставлять участникам всю навигационную иерархию большой интрасети или сайта электронной коммерции, чтобы попросить их организовать эти структуры по своему усмотрению. Участники карточной сортировки — это пользователи, а не разработчики информационной архитектуры. Многоуровневая карточная сортировка гораздо более эффективна в тех случаях, когда потенциальные решения частично определены или ограничены. Даже тогда исследователи и разработчики могут получить больше полезной информации из серии одноуровневых операций сортировки там, где это практически возможно.
10. Древесная сортировка
Древесная сортировка (tree sort — также «сортировка двоичным деревом», «сортировка деревом», «сортировка с помощью бинарного дерева») — это концепция, связанная с карточной сортировкой, но во многих отношениях сильно отличающаяся от нее. По существу, это моделирование «навигационного дерева», которое можно обнаружить в программном приложении или на веб-сайте. Участникам онлайн-сортировки ставят определенные цели, а затем просят перейти к ним, используя модель навигационного дерева. На рисунке 13 этот процесс показан на нескольких экранах (первый этап — первый экран, второй — второй и т. д.). На шаге 1 участник выбрал «Фрукты» (Fruit), а на шаге 2 был выбран пункт «Мягкие плоды» (Soft Fruit).
Если сделан неправильный выбор, то участникам необходимо вернуться назад, чтобы найти более подходящий пункт меню. Участникам может быть предоставлено большое количество заданий, причем при необходимости для каждого из них будет отображаться только произвольное подмножество задач.
По завершении проекта исследователям и разработчикам могут быть представлены показатели результативности, коэффициенты погрешностей и затраченное время (или соответствующие варианты). Хотя «закрытая» карточная сортировка может оказать помощь в процессе валидации дизайна навигации, древесная сортировка в большинстве случаев является более эффективным методом.

Рисунок 13: пример древесной сортировки, используемой в рамках задачи «Найти апельсины» (Find oranges).
Высоких вам конверсий!
По материалам: interaction-design.org
















