



Компьютерная лингвистика — это направление искусственного интеллекта, которое описывает языки с помощью математических моделей. Вы сталкивались с этой наукой, если когда-нибудь пользовались голосовым помощником или онлайн-переводчиком.
Рассказываем, зачем еще нужна компьютерная лингвистика, как она появилась и как стать специалистом в этой области.
Нет времени читать статью? Найдите ее в нашем телеграм-канале и сохраните себе в «Избранном» на будущее.
Содержание статьи
Что такое компьютерная лингвистика?
Задачи компьютерной лингвистики
Как появилась компьютерная лингвистика?
Как применяют компьютерную лингвистику и зачем она нужна?
Научить компьютер различать слова
Извлечь важную информацию из больших объемов текстов
Помочь людям с ограниченными физическими возможностями
Нейролингвистическое программирование и компьютерная лингвистика — это одно и то же?
Как развивается компьютерная лингвистика в России и в мире?
Кто такой компьютерный лингвист и чем он занимается?
Как стать компьютерным лингвистом?
Сколько зарабатывают компьютерные лингвисты?
Попробуйте себя в роли компьютерного лингвиста
Что такое компьютерная лингвистика?
Компьютерная лингвистика — это направление лингвистики, в котором компьютерные технологии применяют для работы с языком.
Например, с помощью этой науки мы научили компьютеры:
- обрабатывать текст, определять его жанр и находить связи между словами;
- переводить с одного языка на другой;
- распознавать речь и преобразовывать аудиозаписи в текст;
- генерировать тексты с нуля.
Нашумевший ChatGPT — тоже продукт компьютерной лингвистики. Вот что чат-бот ответил на вопрос о том, какую роль сыграла эта наука в его создании.

Алгоритм ChatGPT базируется на компьютерной лингвистике
Иногда компьютерную лингвистику называют «вычислительной лингвистикой», но современные ученые считают такой вариант устаревшим — он дает слишком узкое представление о направлении.
Задачи компьютерной лингвистики
- Создавать инструменты для машинного перевода и автоматической генерации текста на иностранном языке.
- Делать информацию доступной для людей, которые не могут читать или писать.
- Обрабатывать большие объемы текстов, которые появляются в Интернете каждый день. Определять важные темы и извлекать из них полезную информацию.
- Разрабатывать системы искусственного интеллекта, способные взаимодействовать с людьми.
- Развивать новые технологии, такие как голосовые помощники и системы автоматической классификации и обработки текста.
Как появилась компьютерная лингвистика?
В 1954 году в Нью-Йорке провели эксперимент по машинному переводу, в котором участвовали представители корпорации IBM и лингвисты Джорджтаунского университета. Его суть заключалась в том, что огромной компьютерной машине (размером с теннисный корт!) предложили перевести 60 предложения с русского языка на английский.
Лингвисты подготовили для машины шесть правил и 250 словарных слов, с помощью которых она и должна была переводить предложения. Текст для перевода подавался с помощью перфокарт (картонок с отверстиями в определенных местах), а результаты отображались на небольшом экране.
Эксперимент прошел успешно, и о нем написали СМИ — все восприняли это событие как большой успех. Несмотря на то, что попытки машинного перевода предпринимались и раньше, именно благодаря успеху Джорджтаунского эксперимента многие страны, в частности США, инвестировали в компьютерную лингвистику. Так началось развитие этого направления.
Как применяют компьютерную лингвистику и зачем она нужна?
Научить компьютер различать слова
Благодаря этому направлению компьютеры научились понимать, что за слово перед ними. И если вы думаете, что это просто, то вы заблуждаетесь.
Например, компьютер усвоил, что глаголы повелительного наклонения обычно оканчиваются на букву «и». Руководствуясь этим правилом, он думает, что фамилия Белуччи — это повелительное наклонение от глагола «белуччить». И таких примеров достаточно много.
Другая проблема в том, что слова могут изменяться по роду, падежу и числу, поэтому для машины формы одного слова выглядят как разные слова. Задача компьютерной лингвистики — исправить эти недостатки.
Вы наверняка пользовались онлайн-переводчиками — без компьютерной лингвистики их бы просто не существовало.
Извлечь важную информацию из больших объемов текстов
Например, большая компания заботится о своей репутации, поэтому нанимает компьютерных лингвистов, чтобы мониторить, что о них пишут в Интернете. Специалисты находят все упоминания компании, чтобы выяснить, как люди относятся к бренду. Вручную такую работу провести невозможно — слишком большие объемы информации.
Помочь людям с ограниченными физическими возможностями
Системы распознавания речи позволяют людям, у которых есть проблемы со зрением, движением или письмом, общаться с помощью компьютера или управлять им голосом. А программы автоматической обработки текста могут преобразовать слова в звук.
Например, у Google есть проект Euphonia, в рамках которого компания собирает образцы голоса людей, страдающих нарушениями речи. Сейчас в базе есть больше 1 000 000 записей общей длительностью 1400 часов. На основе этих записей специалисты улучшат алгоритмы так, чтобы они лучше распознавали разные типы речи.

Компьютерную лингвистику также используют, чтобы разрабатывать программы анализа тональности текста. Они помогают людям с аутизмом распознать социальные сигналы в тексте.
Допустим, человеку пришло сообщение: «Я не ожидал, что ты сделаешь это так поздно, но все равно благодарю тебя». Этот текст содержит и отрицательную, и положительную информацию, поэтому человеку с аутизмом может быть сложно понять, хвалят его или ругают. В этом случае программы анализа тональности могут помочь определить, что сообщение положительное.
Нейролингвистическое программирование и компьютерная лингвистика — это одно и то же?
Нет, это разные вещи.
Нейролингвистическое программирование (НЛП) — это подход к общению, саморазвитию и психотерапии. Приверженцы этой концепции утверждают, будто человек может изменить свои и чужие убеждения, если использовать специальные техники.
Например, сторонники НЛП считают, что можно копировать поведение успешного человека и добиться таких же высот. Упрощенно это выглядит так: вы хотите стать физиком вроде Альберта Эйнштейна, поэтому начинаете одеваться и жестикулировать как он, перенимаете его манеры и так далее.
Научное сообщество признало НЛП псевдонаукой, которая основана на устаревших данных об устройстве мозга. Человеческую психику в ней пытаются приравнять к компьютерной технологии, которую можно «запрограммировать».
Компьютерная лингвистика не имеет к этой подходу никакого отношения. Это научное направление, которое занимается разработкой компьютерных систем для обработки естественного языка.
Результаты работы компьютерных лингвистов — это голосовые помощники, чат-боты, онлайн-переводчики и многое другое.
Как развивается компьютерная лингвистика в России и в мире?
Компьютерной лингвистикой начали заниматься еще с момента появления компьютеров. Но потребность применять эти знания на практике появилась лишь с распространением Интернета и массовым использованием компьютеров.
Прорыв в области компьютерной лингвистики произошел в 2010-х годах, когда появились алгоритмы глубокого обучения (deep learning).
В 2015 году в США появилась компания OpenAI, сотрудники которой занимаются разработкой и продвижением искусственного интеллекта. Один из примеров ее работы в области компьютерной лингвистики — это нейросетевая модель GPT, которая может генерировать тексты на естественном языке.
OpenAI также продвигает компьютерную лингвистику через разные исследовательские проекты. Например, организация открыла доступ к большому количеству данных и кодов для многих проектов, чтобы ученые и программисты могли их использовать в своей работе.
В России тоже есть университеты и научные институты, которые занимаются исследованиями в области компьютерной лингвистики, например Институт системного программирования РАН. Его специалисты разработали инфраструктуру для анализа текстов Texterra, которая позволяет автоматически извлекать информацию из больших баз данных, например из Википедии.
Кто такой компьютерный лингвист и чем он занимается?
Компьютерная лингвистика — это специальность на стыке гуманитарных и технических наук. В один день такой специалист изучает язык, а в другой — программирует.
Компьютерные лингвисты разрабатывают голосовых помощников, таких как Siri от Apple или Алиса от Яндекса, и чат-ботов. Еще одна область их работы — автоисправление ошибок в текстах. Вспомните, как телефон предлагает правильный вариант написания, когда вы опечатались, — это тоже работа компьютерных лингвистов.
Как стать компьютерным лингвистом?
Это достаточно новая специальность, поэтому программ подготовки в России не так много:
- бакалавриат «Фундаментальная и компьютерная лингвистика» в НИУ ВШЭ,
- бакалавриат «Лингвистика в информационно-коммуникационной цифровой среде» в ДВФУ,
- магистратура «Компьютерная лингвистика» в НИУ ВШЭ.
Можно также обратить внимание на направление «Фундаментальная и прикладная лингвистика», например, в УРФУ или РГГУ.
Попасть в компьютерную лингвистику могут и классические лингвисты. Для этого нужно выбрать программу переподготовки, связанную с машинным обучением или искусственным интеллектом. Например, на Coursera есть четырехмесячная программа Natural Language Processing (Обработка текстов на естественном языке).
Сколько зарабатывают компьютерные лингвисты?
В России вакансий для компьютерных лингвистов не очень много, потому что компьютерной обработкой языка занимаются только крупные технологические компании. В феврале 2023 года на HeadHunter доступно только девять вакансий по этой специальности — две из них опубликованы МТС.

В большей части вакансий не указан уровень заработной платы. Скорее всего, он обсуждается индивидуально с каждым кандидатом. Компании, которые указывают з/п, предлагают компьютерным лингвистам с опытом работы 1–3 года от 90 000 руб.
Чаще всего в вакансиях встречаются такие требования:
- высшее профильное образование — теоретическая и прикладная лингвистика или компьютерная лингвистика;
- знание английского языка;
- понимание принципов компьютерной обработки текста;
- знание основ программирования.
Попробуйте себя в роли компьютерного лингвиста
Один из инструментов, которым пользуются компьютерные лингвисты — это языковые корпуса, большие массивы реальных текстов из разных источников. Они нужны, чтобы искать примеры употребления разных слов.
Некоторые лингвистические корпуса есть в открытом доступе и с ними можно поработать. Например, Национальный корпус русского языка (НКРЯ), в коллекции которого можно найти тексты из разных источников. Здесь есть и газетные статьи, и стихи, и даже диалектные тексты. Их общий объем — 1 500 000 000 слов.
Все тексты корпуса размечают профессиональные лингвисты по десяткам параметров:
- частям речи,
- роду,
- числу,
- одушевленности,
- времени, и многому другому.
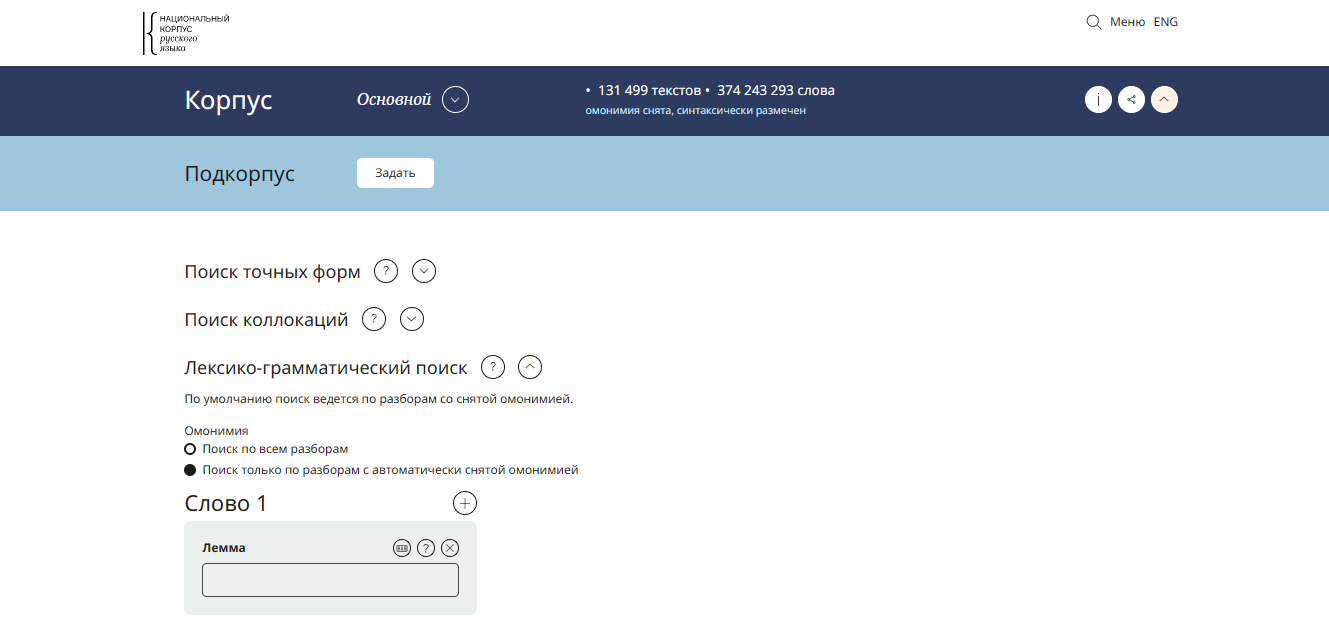
Так выглядит форма поиска в НКРЯ. Найти можно как точное употребление слова, так и его словоформы
В НКРЯ можно:
- Найти самое первое употребление слова. Так, слово «телевидение» впервые написали в 1915 году.
- Узнать, какой из двух синонимов больше употребляют. Например, в XX веке почти в два раза чаще говорили «надо», чем «нужно».
- Выяснить, что Лев Толстой первым из писателей употребил слово «волнительный».
Посмотрите, как устроен самый большой корпус русского языка и как в нем можно искать нужные слова по разным параметрам. Если это покажется интересным, возможно, компьютерная лингвистика для вас.
Высоких вам конверсий!












