



Big Data — это разнообразные данные, поступающие в больших объемах и с огромной скоростью. Информации настолько много, что стандартное программное обеспечение не может обработать такой массив. При этом большие данные полезны — их можно использовать для решения разных задач.
Разбираем на примерах, что такое Big Data и как работают с такими массивами. Наш эксперт Егор Ермилов, Big Data Scientist (ведущий аналитик данных) образовательной платформы «ИнтернетУрок», рассказывает, как собирают большие данные, где их используют и в чем отличие Big Data от Data science.
Нет времени читать статью? Найдите ее в нашем телеграм-канале и сохраните себе в «Избранном» на будущее.
Содержание статьи
Примеры использования Big Data
Amazon
Apple
Visa
Аэропорт Дубая
AT&T
Как собирают и хранят Big Data?
В чем отличие Big Data и Data Science?
Какие технологии Big Data есть?
Как Big Data помогает бизнесу?
Обучение на Big Data аналитика
Сколько зарабатывает Big Data аналитик?
Чем Big Data аналитик отличается от бизнес-аналитика?
Что такое Big Data анализ: техники и методы
Data mining
Машинное обучение
Нейронные сети
Краудсорсинг
Имитационное моделирование
Интересная статистика о Big Data
Что такое Big Data?
Пользователи постоянно генерируют данные: когда совершают покупки, прокладывают маршруты на картах, оставляют поисковые запросы, выходят на пробежку в смарт-часах, публикуют посты в социальных сетях, заказывают еду онлайн и вообще совершают привычные действия. Так получаются большие данные, которые собирают и анализируют разные организации: от производителей машин до социальных служб.
Нет четкой границы, когда данные считаются большими, а когда еще нет. Чаще всего под Big Data имеют в виду терабайты, петабайты и даже зеттабайты информации. К большим данным относится практически любая обезличенная информация о пользователях. Это могут быть:
- пол,
- возраст,
- социальный статус,
- интересы,
- примерный уровень дохода,
- наличие детей и многое другое.
Вычислить конкретного человека в таком массиве данных просто невозможно, да и не нужно. Компании интересуются общими тенденциями, а не отдельными людьми.
Например, Toyota использует большие данные, чтобы предотвратить ситуации, когда водитель случайно нажимает на педаль газа вместо тормоза. Машина анализирует препятствия вокруг и игнорирует нажатие, если определила его как случайное.
Как появились Big Data?
По прогнозам аналитической компании Statista, в 2025 году человечество сгенерирует до 181 зеттабайт данных (1 Збайт = секстиллион байт). Для сравнения в 2020 году было сгенерировано 64,2 Збайта данных.
Гиперрост связан с эволюцией вычислений. Исследовательская компания IDC классифицирует создание и использование данных по трем эпохам:
Где используют Big Data?
Отвечает Егор Ермилов, Big Data Scientist образовательной платформы «ИнтернетУрок»
Большие данные можно использовать везде, но на практике их применяют там, где одновременно есть:
- большой объем данных,
- значимая польза от использования данных,
- средства на поддержание инфраструктуры и специалистов по Big Data.
Чаще всего полноценную Big Data инфраструктуру можно встретить:
- в финансовых организациях — банки и платёжные системы;
- телекоммуникациях — компании мобильной связи;
- транспорте и логистике — авиакомпании и железные дороги.
Иногда Big Data встречается и в науке, например в большой адронном коллайдере.
Примеры использования Big Data
Amazon
Amazon хранит большие данные о клиентах, чтобы адаптировать рекомендации под запросы покупателей. Если добавить что-то в корзину, платформа порекомендует товары, которые часто берут вместе с этим продуктом. Компания генерирует 35% годовых продаж, используя этот метод.
Amazon предлагает товары, которые чаще всего покупают с рассматриваемым товаром. Изображение: Amazon
Apple
Анализируя большие данные, Apple может узнать, как люди используют приложения в реальной жизни, Это позволяет изменять дизайн и начинку программ в соответствии с предпочтениями клиентов.
Еще один пример использования больших данных — это часы Apple Watch. Их носят постоянно, и компания собирает данные о действиях клиентов в течение дня. Эта информация может быть использована для лечения и профилактики болезней, а также для создания мобильных приложений, связанных со здоровьем.

Apple собирает данные о действиях клиентов в течение дня через Apple Watch. Изображение: Tim Foster для Unsplash
Visa
Visa использует большие данные, чтобы выявить мошеннические транзакции. При каждой покупке компания сохраняет такие данные, как местонахождение продавца, сумма транзакции, время суток и сотни других атрибутов. Эти данные сравниваются с прошлым поведением покупателя, и программное обеспечение Visa отправляет в банк оценку о законности покупки. Затем банк может использовать информацию, чтобы быстро принять или отклонить транзакцию.
Visa предлагает пользователям функцию отслеживания местоположения через приложение в телефоне, что особенно актуально при путешествиях. Изображение: Youtube
Аэропорт Дубая
В аэропорту Дубая установлено около 1000 датчиков, используемых для определения пассажиропотока и длины очереди. Полученная информация позволяет персоналу аэропорта решать, как расставить приоритеты в обслуживании. Например, какой самолет должен пристыковываться ближе всего к прибытию и сколько сотрудников требуется на иммиграционных стойках.

Big Data в аэропорту — это пассажиропоток, длина очередей, информация о рейсах, количестве самолетов и сотрудников аэропорта. Изображение: Chris Leipelt для Unsplash
AT&T
C помощью больших данных телекоммуникационная компания AT&T блокирует нежелательные звонки от роботов. Системы ежедневно фильтруют миллиарды записей в поисках шаблонов и подозрительных признаков. Затем обнаруженные аномалии проверяют, чтобы избежать приостановки законных вызовов. Так компании удалось заблокировать 6 500 000 000 звонков от роботов.
Как собирают и хранят Big Data?
Отвечает Егор Ермилов, Big Data Scientist образовательной платформы «ИнтернетУрок»
Можно выделить три эволюционных этапа развития инструментов обработки данных:
- Данных немного. Для их обработки применяются простые инструменты на компьютере аналитиков, например Excel, Python, R. Хранятся данные в виде текстовых и Excel файлов и передаются по электронной почте.
- Данных уже больше. Они обрабатываются на отдельном сервере с бо́льшим количеством оперативной памяти и более мощным процессором. Хранятся в специализированных базах данных, куда имеют доступ разные пользователи.
- Big Data. Уже не хватает мощностей одного большого сервера. Для обработки и хранения требуется параллельные вычисления и кластер из многих серверов.
Область применения во всех трёх случаях может быть одинаковой: от аналитических отчетов до моделей машинного обучения.
В чем отличие Big Data и Data Science?
Отвечает Егор Ермилов, Big Data Scientist образовательной платформы «ИнтернетУрок»
Data Science — наука о данных. Она нужна, чтобы учиться извлекать из данных пользу для бизнеса.
Big Data — это такое состояние, когда накоплен большой объём данных и с ним нужно как-то работать. А традиционные инструменты уже не справляются.
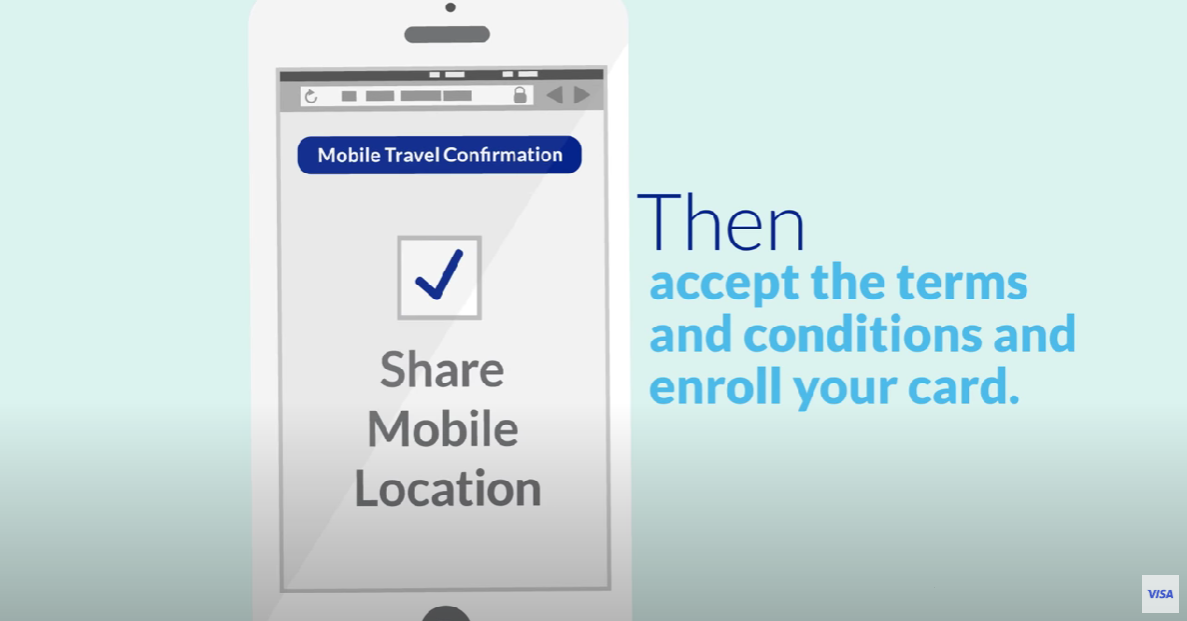
Нет однозначного представления о том, где лежит граница между «еще не big data» и «уже big data». Но традиционно выделяют три V или три основных признака больших данных:
- Volume (объем). Привычные инструменты не могут хранить большой объём данных. Речь идет уже о терабайтах данных, которые не вмещаются в традиционные базы и тем более в Excel-файлы.
- Velocity (скорость). Имеется в виду как скорость прироста новых данных, так и необходимая скорость обработки. Раньше хватало работы аналитика и ручной обработки Excel в течение пары дней. Теперь бизнесу нужно видеть отчёты, формирующиеся в режиме реального времени.
- Variety (многообразие). Это значит разнообразие форм хранения данных. Нужно уметь хранить и анализировать не только табличные данные, но и, например, фото-, видео- и аудио- данные.
У Big Data такая же область применения, как и у Data Science, но другой набор инструментов. Если нужно проанализировать, как вели себя пользователи прошлый месяц — это в раздел аналитики больших данных. Если нужно на основе накопленных данных предсказать, как поведут себя пользователи в следующем месяце — это в раздел машинного обучения. Всё это позволяет делать выводы из накопленных данных, предсказывать состояние дел на будущее и принимать решения.
Какие технологии Big Data есть?
Технологии больших данных — это программы, которые предназначены для анализа, обработки и извлечения информации из больших наборов данных со сложной структурой. Они нужны, когда традиционных технологий недостаточно.
SQL и NoSQL
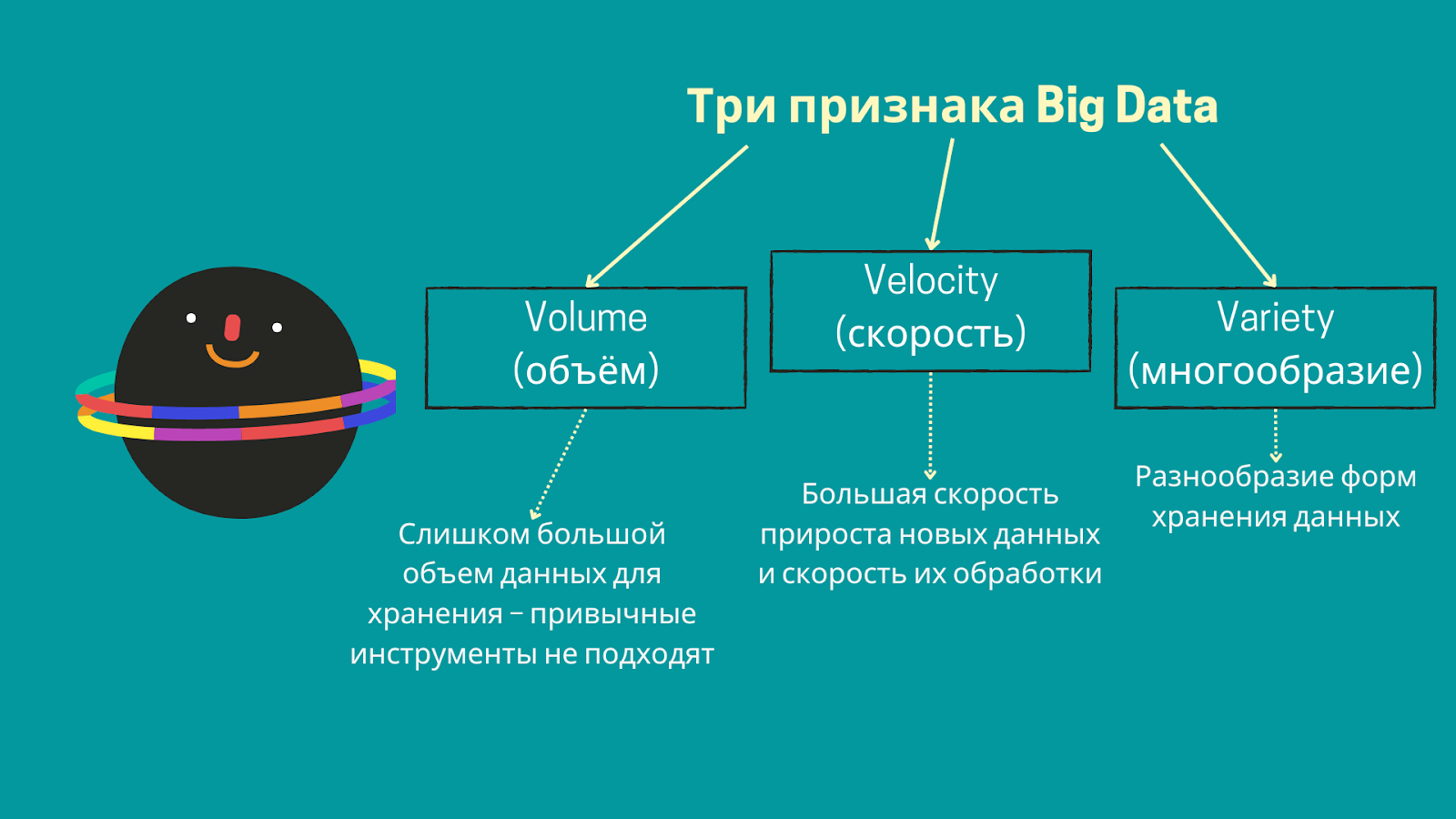
Базы данных бывают двух типов:
- Реляционные, где информация представлена в виде таблиц. Для работы с ними используют язык запросов SQL.
- Нереляционные — все остальные базы, в которых информация представлена по-другому, например в виде графов или коллекции документов. Для работы с ними используют язык запросов NoSQL.
NoSQL более гибкие и позволяют решать больше задач, например, они подходят, чтобы хранить данные кэша или информацию для алгоритмов рекомендаций. Нереляционные базы используют, когда нужны масштабы и быстрота обработки, — как в случае с большими данными.
MapReduce
Это модель данных и алгоритм, которые нужны для больших вычислений, где нужно задействовать несколько компьютеров параллельно. MapReduce может обрабатывать десятки петабайт данных в день (1 Петабайт = 1 024 Терабайт). Сначала информация фильтруется по условиям запроса, а затем распределяется между компьютерами, каждый из которых рассчитывает свои блоки данных и передает результаты.
MapReduce используют для создания поискового индекса, выявления спама в почте, оптимизации рекламы. Самая популярная программа, работающая по алгоритму MapReduce, — это Hadoop.

Скриншот с сайта Hadoop
R
Это язык программирования, предназначенный для обработки данных — на нем даже строят машинное обучение и нейросети. R помогает анализировать данные из разных источников и полезен при работе со статистикой.
Как Big Data помогает бизнесу?
Отвечает Егор Ермилов, Big Data Scientist образовательной платформы «ИнтернетУрок»
Data Science, как и Big Data, позволяет компаниям выработать так называемый подход, основанный на данных (data-driven approach). Это такой подход к управлению, при котором решения принимаются, опираясь на анализ данных и математику. А интуиция и личный опыт отходят на второй план.
Раньше, например, выбирая между вариантами А и Б, решение принимали на основе прошлого опыта менеджеров, их здравого смысла и интуиции. Анализ больших данных сейчас может цифрами показать разницу между А и Б — это позволяет принять более объективное решение.
Наука о данных также может учесть уже накопленный опыт принятия решений: как со стороны руководства компаний, так и со стороны клиентов. Обученная математическая модель позволяет принимать рутинные решения без участия человека, при этом гораздо быстрее и точнее.
Пример таких решений:
- Когда лучше устроить распродажу?
- Какую установить скидку на разные категории товаров?
- Какой товар предложить купить?
- Какие клиенты больше склонны купить товар или услугу?
Кто такой Big Data аналитик?
Big Data аналитик — это специалист по анализу больших данных, который собирает их в базы, изучает и делает выводы. Этот человек должен извлечь информацию, которая поможет компании принять стратегически верные решения. Big Data аналитики нужны компаниям, куда поступают большие объемы данных: в IT-секторе, у мобильных операторов, в банках и государственных организациях.
Обучение на Big Data аналитика
В России пока нет отдельного бакалавриата по специальности Big Data аналитик, но для старта в профессии подойдут направления подготовки, связанные с IT, математикой и компьютерными науками. Например, прикладная информатика или программная инженерия. В Высшей школе экономики есть англоязычная магистерская программа «Бизнес-аналитика и системы больших данных» — она подойдет тем, кто хочет углубить свои знания после бакалавриата.
Другой вариант обучения — курсы. Чтобы получить представление о работе с Big Data, можно воспользоваться бесплатными программами:
- курс университета МИСиС «Введение в инженерию больших данных»;
- курс Санкт-Петербургского Политехнического университета «Наука о данных и аналитика больших объемов данных»;
- курс университета ИТМО «Обработка и анализ больших данных».
Анализу больших данных обучают также онлайн-школы вроде GeekBrains, Нетологии и Яндекс.Практикума.
Сколько зарабатывает Big Data аналитик?
Зарплата аналитика больших данных в России зависит от уровня компетенций:
В США, по данным сайта по поиску вакансий Indeed, зарплата начинающего Big Data аналитика в среднем составляет $4 800 в месяц, а аналитик с опытом работы от 3 лет получает $5 369. Вот компании США, которые платят Big Data аналитикам больше остальных:
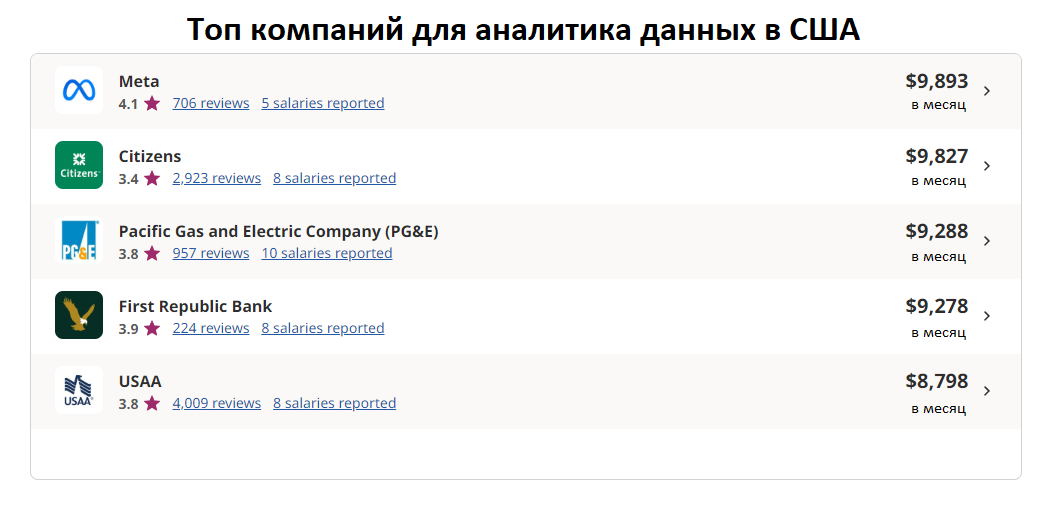
Скриншот с сайта Indeed
Чем Big Data аналитик отличается от бизнес-аналитика?
Big Data аналитик и бизнес-аналитик интерпретируют данные и делают выводы на их основе. Но это разные профессии с такими ключевыми отличиями:
Что такое Big Data анализ: техники и методы
Анализ Big Data — это сбор, хранение и анализ большого количества информации, которая поступает из разных источников. Вот какие техники и методы в этом помогают.
Data mining
Поиск важных данных среди огромного массива накопившейся информации — по сути, это превращение необработанных данных во что-то полезное. Эту технологию используют, чтобы найти неизвестные ранее закономерности между данными. Например, маркетплейсам Data mining помогает выявить взаимосвязи между покупками и подстроить рекомендации под пользователя.
Машинное обучение
Это искусственный интеллект, который обучается на массивах данных и принимает решения, анализируя схожие задачи. Впоследствии он выявляет закономерности, учится на прошлом опыте и генерируют новые решения.
Нейронные сети
Один из видов машинного обучения — искусственный интеллект, который имитирует, как нейроны человеческого мозга передают сигналы. Нейросетям дают огромный массив правильно решенных задач, и те на их основе принимают решения. Другой алгоритм говорит, правильно ли принято решение, — со временем результаты становятся все более точными. На нейросетях работают голосовые помощники и чат-боты.
Краудсорсинг
С английского краудсорсинг дословно переводится как «использование ресурсов толпы». Это явление, когда для решения проблемы привлекают внешних исполнителей, добровольцев. Например, Microsoft предлагает тысячам пользователей отправлять отчеты об ошибках в компанию — эта стратегия позволяет быстро выявить баги и исправить их в обновлении.
Имитационное моделирование
Имитационное моделирование — это построение точных компьютерных моделей на основе Big Data, которые затем испытывают и делают прогнозы. На основе имитационного моделирования можно изучить поведение покупателей в зависимости от меняющихся обстоятельств.
Интересная статистика о Big Data
- В 2020 году человечество сгенерировало 64,2 Збайта данных. К 2021 году из них сохранилось только 2%.
- По состоянию на 2022 год, 90% мировых данных было создано за предыдущие два года.
- В 2022 году больше всего центров обработки данных находится в США — 2 701 центр. В России их только 172.

Составлено по материалам Statista
- 92,1% самых крупных компаний США получают отдачу от инвестиций в работу с данными и искусственным интеллектом.
- К 2024 году соотношение между уникальными и скопированными данными составит 1:10. Это значит, что на каждый уникальный файл будет приходиться 10 неуникальных.
Высоких вам конверсий!










: что это и как выбрать")

























