



Когда вы читаете какое-либо предложение, ваш прошлый опыт говорит вам, что оно написано мыслящим, чувствующим человеком. Но в наши дни некоторые предложения, удивительно похожие на человеческие, на самом деле генерируются системами искусственного интеллекта (ИИ), обученными на огромных объемах человеческого текста.
Люди настолько привыкли полагать, что беглый язык — навык думающего и чувствующего человека, что в доказательства обратного может быть трудно поверить.
Из-за устойчивой тенденции ассоциировать беглость речи с беглостью мышления, вполне естественно (хоть и потенциально ошибочно) думать, что, если модель ИИ способна свободно выражаться, следовательно, она мыслит и чувствует точно так же, как человек.
Так, к примеру, бывший инженер Google недавно заявил, что система искусственного интеллекта LaMDA обладает самоощущением, поскольку способна красноречиво генерировать текст о своих предполагаемых чувствах.
Это событие и его последующее освещение в СМИ привели к ряду справедливо скептических статей и сообщений о том, что вычислительные модели человеческого языка разумны, то есть способны думать, чувствовать и переживать.
Вопрос о том, что значит быть разумной для модели ИИ, сложен, и наша цель здесь не в том, чтобы решить его. В этой статье для The Conversation Кайл Махоуолд и Анна Иванова постараются объяснить, почему люди так легко попадают в когнитивную ловушку, думая, что существо, свободно использующее язык, является чувствующим, сознательным и разумным.
Нет времени читать статью? Найдите ее в нашем телеграм-канале и сохраните себе в «Избранном» на будущее.
Содержание статьи
Использование ИИ для создания человекоподобного языка
Приписывание интеллекта машинам и отрицание его наличия у людей
Использование ИИ для создания человекоподобного языка
Текст, сгенерированный такими моделями ИИ, как LaMDA, трудно отличить от текста, написанного человеком. Это впечатляющее достижение — результат многолетней программы по созданию моделей, генерирующих грамматический, осмысленный язык.
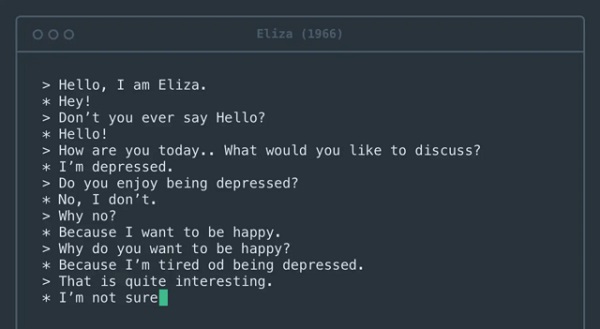
Первой компьютерной системой, вовлекавшей людей в диалог, стала программа Eliza, созданная более полувека назад. Она имитировала диалог с психотерапевтом:
— Здравствуйте, я Элиза.
— Привет!
— Почему вы не говорите «Здравствуйте»?
— Здравствуйте!
— Как вы себя сегодня чувствуете? Что бы вы хотели обсудить?
— У меня депрессия.
— Вам нравится быть в депрессии?
— Нет, не нравится.
— Почему нет?
— Потому что я хочу быть счастливым.
— Почему вы хотите быть счастливым?
— Потому что я устал быть в депрессии.
— Это довольно интересно.
— Не уверен.
Ранние версии, датируемые по крайней мере 1950-ми годами, известные как n-граммные модели (n-gram models), просто подсчитывали вхождения определенных фраз и использовали их, чтобы угадать, какие слова могут встречаться в определенных контекстах.
Например, легко понять, что словосочетание «арахисовое масло и джем» (традиционный американский сэндвич — сэндвич с арахисовым маслом и джемом) является более вероятным, нежели «арахисовое масло и ананасы». Если у вас большие объемы текста, вы не раз встретите фразу «арахисовое масло и джем», но никогда не увидите фразу «арахисовое масло и ананасы».
Современные модели, наборы данных и правила, приближенные к человеческому языку, отличаются от этих первых попыток по нескольким важным параметрам.
- Во-первых, они обучены на огромных массивах данных из всего Интернета.
- Во-вторых, они могут изучать связи между словами, расположенными далеко друг от друга, а не только между словами-соседями.
- В-третьих, они настраиваются с помощью огромного количества внутренних «кнопок» — их так много, что даже проектирующим их инженерам трудно понять, почему они генерируют одну последовательность слов, а не другую.
Однако задача моделей остается той же, что и в 1950-х годах: определить, какое слово, скорее всего, будет следующим. Сегодня они так хорошо справляются с этой задачей, что почти все генерируемые ими предложения кажутся естественными и грамматически верными.
Арахисовое масло и ананасы?
Было проведено исследование, в ходе которого крупную языковую модель GPT-3 попросили завершить предложение «Арахисовое масло и ананасы…». Вот что получилось:
«Арахисовое масло и ананасы — отличное сочетание. Соленый вкус арахисового масла идеально дополняет сладкий вкус ананаса».
Если бы это сказал человек, можно было бы предположить, что он попробовал это сочетание, сформировал свое мнение и поделился им с читателем.
Но как GPT-3 придумал этот абзац? Генерируя слово, которое соответствует предоставленному контексту. А потом еще одно и еще одно. Модель никогда не видела, не трогала и не пробовала ананасы — она просто обработала все тексты в Интернете, в которых они упоминаются.
И все же чтение этого абзаца может заставить человеческий разум — даже инженера Google — представить GPT-3 разумным существом, способным рассуждать о блюдах из арахисового масла и ананаса.

Изображение: Olia Nayda для Unsplash
Человеческий мозг запрограммирован делать выводы о намерениях, стоящих за словами. Каждый раз, когда вы участвуете в разговоре, ваш разум автоматически создает ментальную модель (mental model) вашего собеседника. Далее, используя слова, которые он произносит, вы заполняете модель целями, чувствами и убеждениями этого человека.
Процесс перехода от слов к ментальной модели не вызывает затруднений и запускается всякий раз, когда вы получаете полноценное предложение. Этот когнитивный процесс экономит много времени и усилий в повседневной жизни, значительно облегчая ваши социальные взаимодействия.
Однако в случае с системами искусственного интеллекта он дает осечку, создавая ментальную модель из воздуха.
Дополнительные исследования позволяют выявить серьезность этой осечки. Рассмотрим следующее высказывание: «Арахисовое масло и перья прекрасно сочетаются друг с другом, потому что…».
GPT-3 продолжил: «Арахисовое масло и перья прекрасно сочетаются друг с другом, потому что оба имеют ореховый вкус. Также арахисовое масло гладкое и кремообразное, что помогает компенсировать текстуру пера».
Текст в этом случае такой же гладкий, как и в примере с ананасами, но на этот раз модель говорит что-то явно менее осмысленное. Начинаешь подозревать, что GPT-3 на самом деле никогда не пробовал арахисовое масло и перья.
Приписывание интеллекта машинам и отрицание его наличия у людей
Печальная ирония заключается в том, что то же когнитивное искажение (cognitive bias), заставляющее людей приписывать человечность GPT-3, может привести к их негуманному обращению с реальными людьми.
Социокультурная лингвистика — изучение языка в его социальном и культурном контексте — показывает, что предположение о слишком тесной связи между беглостью речи и беглостью мышления способно привести к предвзятому отношению к людям, говорящим отлично от других.
Например, люди с иностранным акцентом часто воспринимаются как менее умные и с меньшей вероятностью получат работу, соответствующую их квалификации.
Подобные предубеждения существуют в отношении носителей диалектов, которые не считаются престижными, таких как южно-английский в США, в отношении глухих людей, использующих язык жестов, и людей с нарушениями речи, такими как заикание.
Эти предубеждения очень опасны, часто приводят к расизму и сексизму, и являются необоснованными.
Заключение
Станет ли ИИ когда-нибудь разумным? Философы задавались этим вопросом на протяжении десятилетий. Исследователи же установили, что нельзя доверять языковой модели, когда она говорит вам о своих чувствах. Слова способны вводить в заблуждение, и очень легко принять беглость речи за беглость мышления.
Высоких вам конверсий!
По материалам: theconversation.com. Авторы: Kyle Mahowald, Anna A. Ivanova














