



Парсинг — это автоматизированный способ сбора и систематизации данных из различных интернет-источников. Для получения информации нужен специализированный сервис — парсер.
Парсер — это автоматизированная система, для которой вся информация в сети представлена в виде кода или текста. Он собирает информацию практически из любых источников в 3 шага: сканирует ресурс → находит заданные параметры → составляет отчет.
Парсер ищет данные на обычных сайтах, интернет-магазинах, социальных сетях и каталогах.
Разберем, как спарсить данные с любого сайта без навыков программирования.
Содержание статьи
Преимущества и недостатки парсинга
Способы использования парсинга
Шаг 1. Выбираем объект парсинга
Шаг 2. Выбираем источники
Как парсить фото и иллюстрации?
Зачем нужен парсинг?
Маркетолог ежедневно работает с большим объемом данных. Он анализирует работу сайта, отслеживает конкурентов, интересы аудитории и другие данные. Этот процесс можно делать вручную или автоматизировать с помощью специальных утилит — парсеров.
Если ваша цель систематизировать общедоступные данные для улучшения контента, экономии бюджета при продвижении и развитии бизнеса — использование парсера законно.
Ограничения по парсингу
Общедоступной информацией для решения личных или коммерческих задач может пользоваться любой человек. Ограничения распространяются на парсинг популярного авторского контента. Его можно парсить, но использовать без разрешения владельца — нельзя.
Нельзя также использовать собранные данные для спам-рассылок, плагиата, DDOS-атаки, взлома сайтов и распространения личных данных пользователей.
Это недобросовестные действия, которые нарушают закон, правила работы в поисковых системах и соцсетях. За них грозят штрафы, санкции и блокировка.
Если хотите на своем сайте собирать персональные данные, предупредите посетителей об этом.
Преимущества и недостатки парсинга
Автоматический сбор информации имеет несколько преимуществ:
- Самостоятельная работа. Специалист ставит задачу, а парсер находит и сортирует данные по указанным параметрам при наличии стабильного доступа к Интернету. Время работы не ограничено. Программа может собирать сведения 24 часа в сутки без перерывов.
- Анализ и систематизация. Специалист указывает один или несколько параметров, по которым парсер сводит сведения. Количество настроек не ограничено. Готовый отчет содержит только необходимый контент без спама, ошибок или нерелевантной информации.
- Отсутствие ошибок. При использовании парсера человеческий фактор исключен. Программа не устает и не допускает ошибки по невнимательности.
- Удобный отчет. Парсер формирует сведения в удобной форме. Пользователь настраивает форму отчета сам.
- Распределение нагрузки. Парсер учитывает требования по частоте обращений к сайту и минимизирует риск взлома чужого сайта. Вас не обвинят в умышленной DDOS-атаке.
Единственный существенный недостаток парсинга — невозможность сбора данных с ресурсов с запретом на автоматический сбор сведений.
Владелец чужого сайта может запретить собирать данные по IP-адресам, включить настройки блокировки для поисковых ботов. Во всех остальных случаях парсинг — это быстрый и надежный способ сбора информации.
Если вы не хотите, чтобы конкуренты парсили ваш сайт, заблокируйте сторонние запросы через robots.txt или настройте капчу. Хотя эти способы не дают 100% защиты от парсинга конкурентов.
Обойти блокировку можно двумя способами:
- Настроить отображение бота по именем YandexBot, Googlebot и проверить отсутствие блокировки на эти имена в site.ru/robots.txt/IP.
- Включить VPN Капча для автоматического распознавания капчи.
Как работает парсинг?
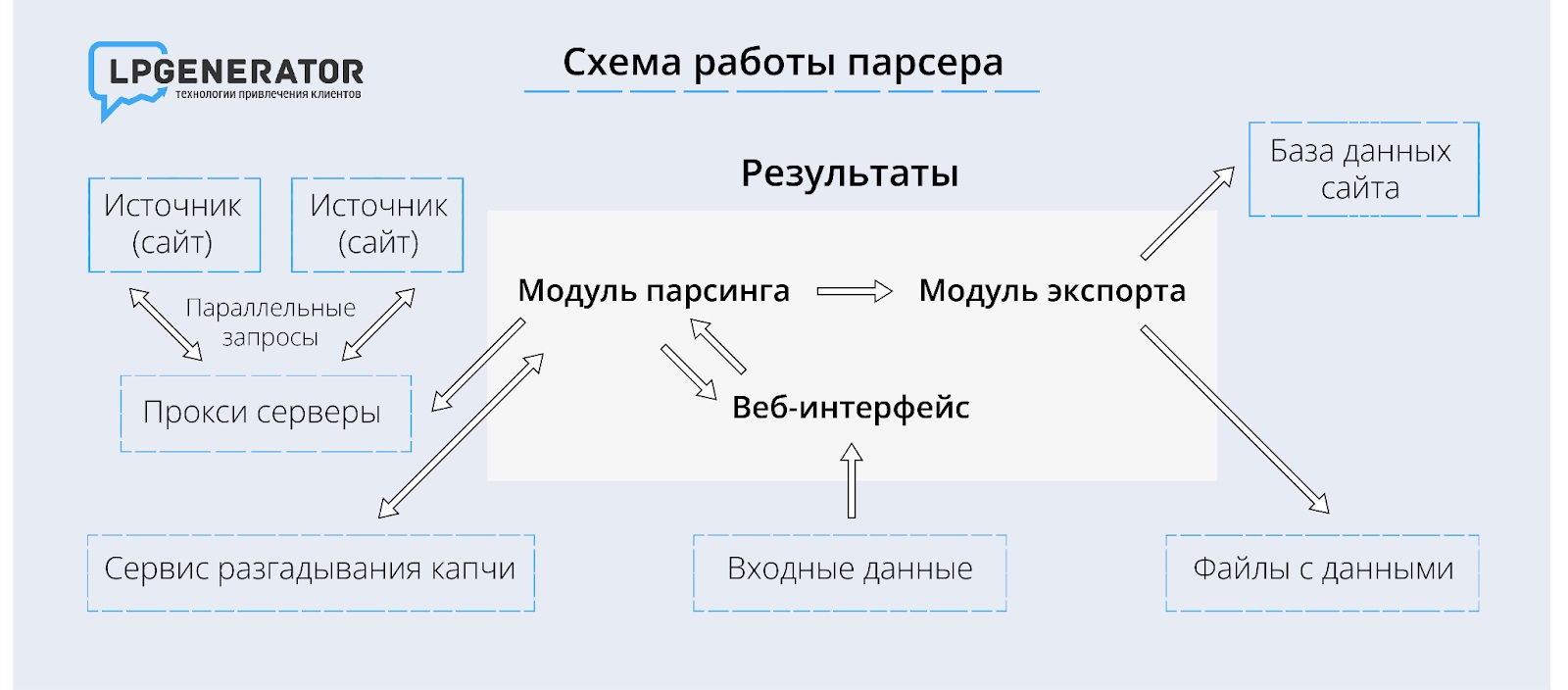
Принцип работы сервисов примерно одинаков:
- Программа отправляет запрос на нужный URL-адрес и получает HTML-код с информацией.
- Парсер распознает код, трансформирует его в текст, создает структуру в памяти компьютера. Фактически он обратно преобразует HTML-код в заголовки, подзаголовки, абзацы, жирные выделения и т. д.
- Парсер систематизирует и сохраняет сведения в файле с расширением .txt, .xls, .html и др.
Способы использования парсинга
Парсер используют в двух случаях:
Когда анализируют собственный сайт.
Когда изучают ресурсы конкурентных фирм, ищут тенденции и контент.
В чистом виде тот или иной способ используют редко. Для комплексной оценки ситуации специалисты совмещают оба метода.
Например, анализируя цены других компаний из отрасли, они учитывают диапазон цен заказчика. При наличии новинок они ищут аналогичные товары в собственной базе и сравнивают их между собой.
Как парсить цены?
Есть несколько сервисов, которые помогут решить корпоративные задачи:
- Screaming Frog SEO Spider.
- Mozenda.
- Automation Anywhere.
- Content Grabber.
- Netpeak Spider.
- FMiner и др.
Если ни одна из программ не решает поставленной задачи, вы можете написать парсер самостоятельно при помощь любого языка программирования: PHP, C++, Python.
Если парсер нужен для одного параметра на странице, используйте XPath — язык, позволяющий парсить XML-документы. Разберем, как работает XPath на конкретном примере.
Шаг 1. Выбираем объект парсинга
Например, нужно собрать цены продуктов из каталога конкурента. Перейдите на нужную страницу, правой кнопкой нажмите на цифру с ценой и выберите «Посмотреть код элемента».
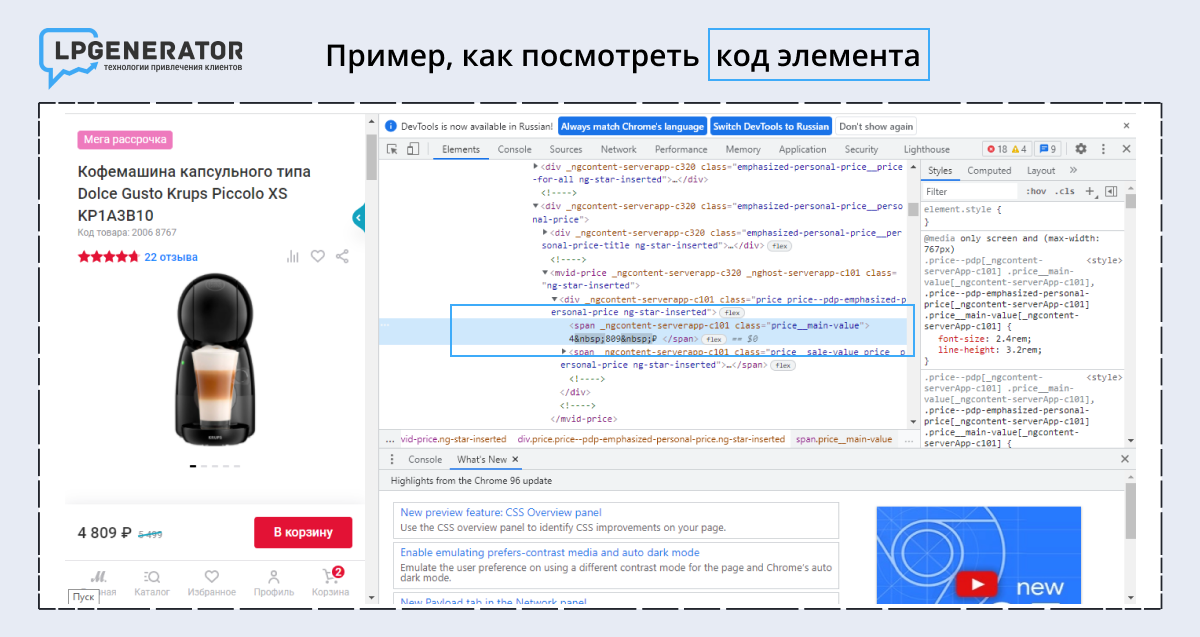
Теперь правой кнопкой мыши нажмите на <span> → Copy → XPath. Вы скопировали строку из HTML-кода, где написана необходимая информация, и определили границы будущего парсинга.
Если на другой странице верстка будет другой, копирование XPath не поможет. Парсер не соберет нужную информацию. В таком случае используйте справочники по языку XPath. В них собраны участки кода xpath.
Когда кусочек кода выделен, выбирайте парсер, например Screaming Frog. Он бесплатно анализирует 500 страниц: проверяет пустые title, дубликаты, заголовки, незаполненные метатеги и битые ссылки. Для парсинга нужна платная версия.
Откройте программу и укажите параметры настройки:
- Для сбора цен перейдите Configuration → Custom → Extractions и сформируйте запрос. В нашем примере нужная информация обозначена метатегом <span> с классом price_main-value. XPath-запрос выглядит так: //span[@class="price_main-value"]/span
- Чтобы получать данные в текстовом виде, поставьте галочку в выпадающем меню справа напротив Extract Text.
Шаг 2. Выбираем источники
Теперь выберите страницы, с которых нужно собирать данные. Если вставить ссылку на главную страницу сайта в Screaming Frog, в выборку попадут информационные страницы без цен. Для сокращения времени, необходимого на парсинг, выберите конкретный перечень страниц, по которым программа сделает выборку.
Перейдите в карту сайта — «адрес сайта/sitemap.xml» или в robots.txt — site.ru/robots.txt и выберите товарные карточки.
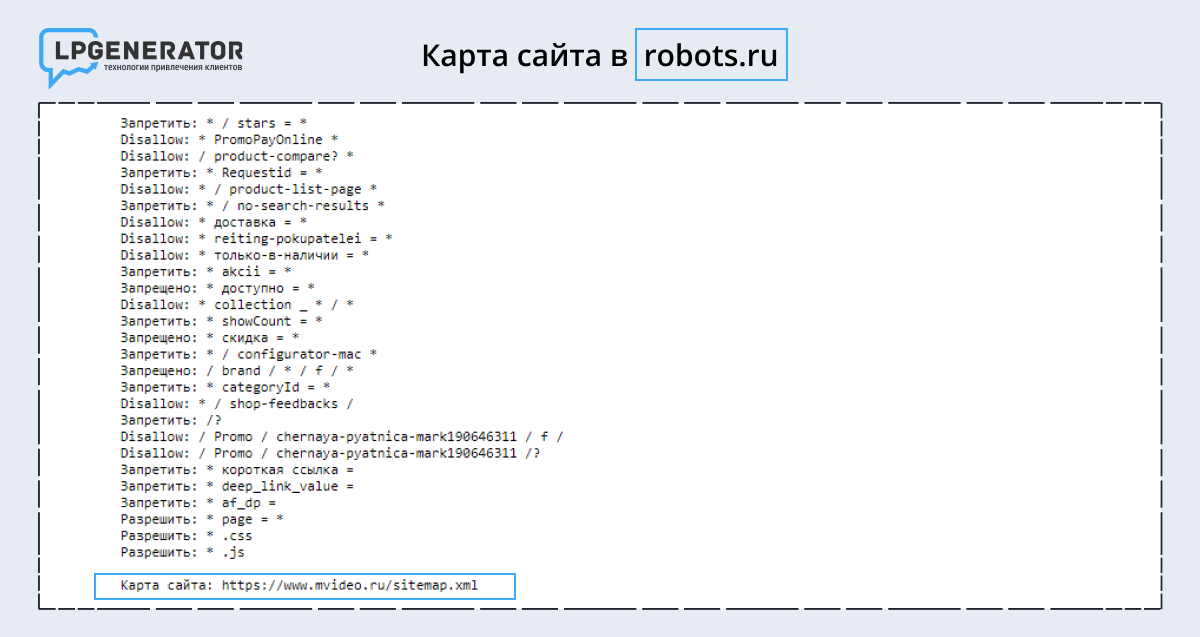
Если карты сайта нет, систематизировать данные не получится. Запускайте парсинг в стандартном режиме по всем страницам сайта. Программа соберет нужные сведения, но потратит больше времени.
Выбирайте страницы, касающиеся товаров, с надписью — Product.

Ссылочную массу выгружайте в раздел Mode → List → Upload → Download Sitemap. Введите гиперссылку с картой сайта, в которой сгруппированы товарные позиции и нажмите ОК. Парсер формирует выборку и выводит на экран.
Раздел Internal отражает данные по всем параметрам:
- код ответа;
- возможность индексации;
- title, description и т. д.
Для просмотра цен нажмите на стрелку в правом верхнем углу. В выпадающем меню выберите Custom → Filter → Extraction. Парсер покажет перечень страниц с товарами и цены на них. Для выгрузки данных нажмите Export.
Чтобы к списку добавить названия товаров, перейдите в Configuration → Custom → Extraction, вставьте дополнительный XPath-запрос, а затем повторно запустите парсер. Проверяйте, как пишется нужный элемент html-кода в справочнике или в sitemap.xml.
Парсить информацию таким образом можно почти с любого сайта, кроме защищенных ресурсов. Например, скопировать данные из Яндекс.Маркета не выйдет.
Как парсить фото и иллюстрации?
Крупные интернет-магазины размещают на сайте фото от поставщиков. Они универсальные и могут использоваться в любом каталоге.
Специалисты собирают в таблицы ссылки на картинки из разных карточек, чтобы позже выбрать нужный файл и загрузить на свой сайт.
Большинство систем для управления сайтов, например Bitrix или Shop-Script, разрешают прикреплять ссылки вместо загрузки фото. Через эти движки можно выгружать изображения прямо из CSV-файла.
Чтобы запустить парсинг картинок, выделите код и сформулируйте XPath-запрос:
1. Правой кнопкой мыши нажмите на фотографию и выберите «Посмотреть код объекта».
2. Найдите строку кода и выделите в элементе <span> нужный тег.
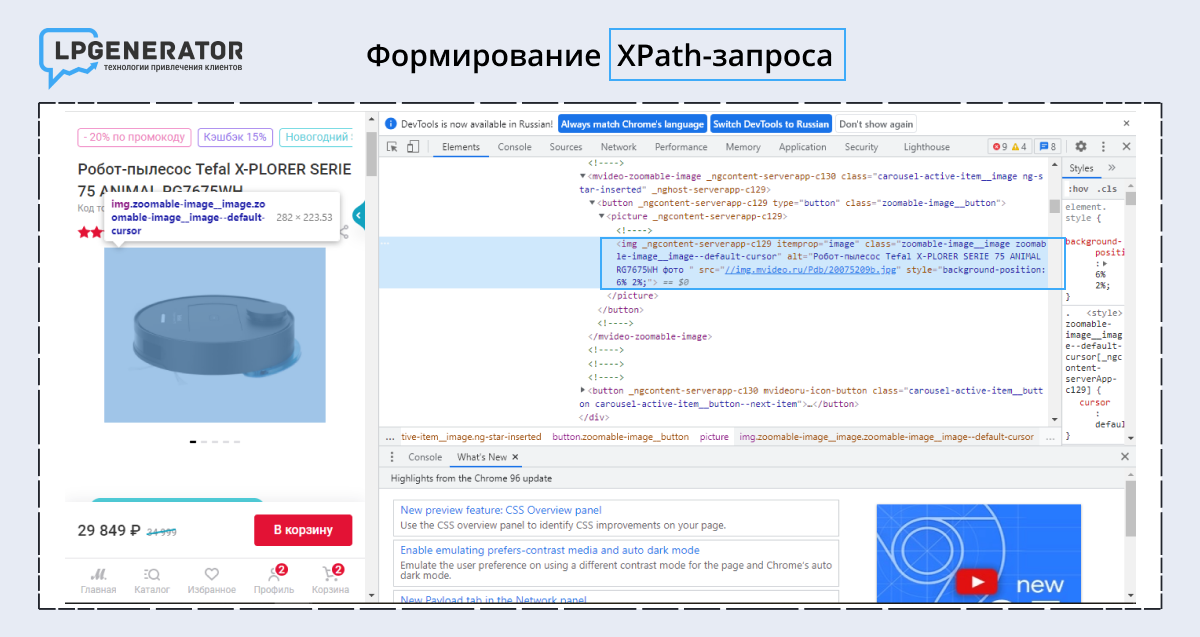
3. Сформулируйте XPath-запрос: //*[@id="firstbackground-position"]/*/img/@src
Запрос обращен к идентификатору firstbackground-position — первой фотографией из списка, а также вложенным в него элементам. Они перечислены под * «звездочкой».
Метатег img указывает на строку с указанным URL-адресом. Он покажет парсеру, где брать информацию.
4. Откройте Screaming Frog и перейдите во вкладку Configuration → Custom → Extraction.
5. Вставьте XPath-запрос и нажмите ОК.
Таким способом можно спарсить одну фотографию или весь каталог:
- Для добавления одного изображения скопируйте ссылку и вставьте ее в парсер Upload → Paste.
- Чтобы скопировать ссылки по всем фотографиям, опубликованным на ресурсе, выберите вкладку Mode → Spider, введите ссылку на сайте и запустите программу.
Конкретизировать страницы при сборе фотографий не надо. Парсер пропустит разделы, в которых нет иллюстраций.
Если собранные фотографии нужно идентифицировать по артикулу или названию, добавьте еще один XPath-запрос. Специалисты часто собирают связку: наименование товара под метатегом Н1, артикул, иллюстрация.
Как парсить описание товаров?
Перед покупкой покупатели читают информацию о продукте. Чем больше характеристик указывает продавец, тем выше шанс, что клиент оформит заказ.
Собирать данные вручную долго и сложно. Автоматизировать процесс и свести данные в Excel-таблицу также помогает парсер.
Последовательность действий та же:
- Нажмите правой кнопкой мыши на название характеристики, которую хотите выделить. Например, «количество режимов работы» у робота-пылесоса.
- Выберите «Посмотреть код объекта» и найдите строку с HTML-кодом.
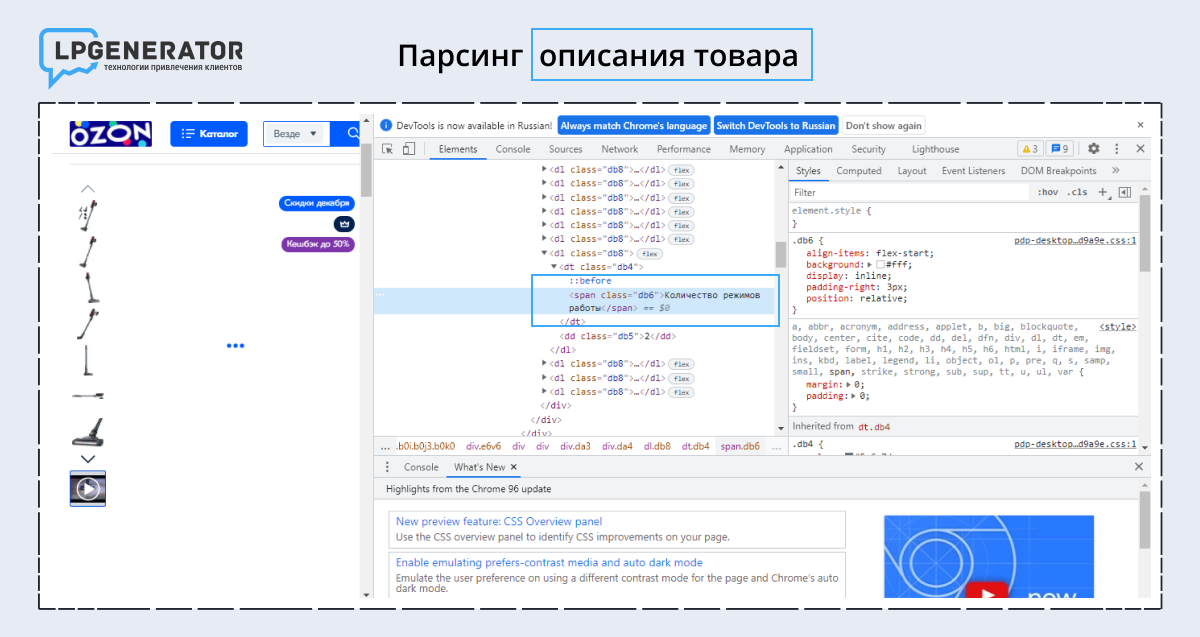
В данном случае описание находится под тегом <span>. Технические характеристики и описания к ним указаны внутри элемента <span>.
- Для парсинга нужны элементы <span> с идентификатором «количество режимов работы». XPath-запрос выглядит так: //*[@class="количество режимов работы"]
- Откройте парсер Screaming Frog и введите параметр поиска: Configuration → Custom → Extraction → Extract Text.
- Переключитесь в режим List. Он находится во вкладке Mode.
- Выберите Upload, укажите ссылку на страницу и начните парсинг.
- По окончании поиска перейдите в раздел Custom → Extraction.
Программа соберет все параметры, указанные под тегом <span>. Например, в количестве режимов отразится характеристика «2».
Заключение
Парсинг — это удобный способ получения информации для развития бизнеса. Он автоматизирует и ускоряет сбор данных, снимает часть нагрузки со специалиста и минимизирует ошибки.
Высоких вам конверсий!













